
Antes de começarmos, vale a pena dedicar um breve momento para me apresentar aos senhores. Meu nome é Mark (ou @integralist se o Twitter for sua ferramenta de comunicação preferida) e atualmente trabalho para a BBC News em Londres, Inglaterra, como engenheiro principal/líder de tecnologia; e também sou o autor de “Pro Vim“.
Um rápido agradecimento ao Steven Jack que dedicou seu tempo para revisar esta postagem. Ele ajudou a instigar ou foi uma parte fundamental do sucesso de muitas das coisas que fizemos bem
O site “responsivo” da BBC News recebe aproximadamente 8 milhões de visitas por dia (em média, em um dia tranquilo de notícias). Esses números serão muito maiores quando o site responsivo substituir a atual oferta estática para desktop e começar a atrair muito mais usuários. Mas, por enquanto, isso dá uma ideia aproximada do tipo de tráfego que recebemos diariamente.
Esta postagem tem como objetivo fazer um tour pelos diferentes pontos de discussão de arquitetura e design de código que surgiram em um momento ou outro enquanto eu trabalhava na BBC. Vamos dar uma olhada em algumas infraestruturas de sistema de alto nível em uma tentativa de fornecer aos senhores um pouco de “alimento para o pensamento” sobre esses tópicos. Falarei sobre algumas técnicas e ferramentas que funcionam para nós, e também veremos algumas que não funcionaram tão bem. Sempre fiquei intrigado com a forma como outros desenvolvedores trabalham e pensam sobre diferentes tipos de problemas, portanto, vamos considerar isso uma experiência de compartilhamento de conhecimento de mim para o senhor.
Observação: os pensamentos e comentários aqui são meus e não representam necessariamente os de meu empregador. Sim, eu tinha que ir até lá… só por precaução
Alguns leitores provavelmente não terão que se preocupar com o mesmo tipo de problemas de escalabilidade com os quais a BBC tem que lidar ao projetar/criar sistemas e aplicativos. Mas isso não quer dizer que as informações e os pensamentos que vou compartilhar com os senhores neste post não sejam transferíveis. Na verdade, muito do que discutirei são conceitos que podem ser utilizados em aplicativos de qualquer tamanho (porque um bom design é eficaz em qualquer escala).
Observação: esta postagem aborda muito pouco sobre tecnologias e técnicas de front-end. Esse tópico de discussão é muito mais vasto e foi abordado substancialmente nos últimos anos (especialmente o tópico de desempenho, que, desde 2007, foi trazido para a mentalidade dominante dos engenheiros de front-end pelo Steve Souders.
Então, sem mais delongas, vamos começar…
Complexidade vs Complicado
Ao descrever um software, o senhor frequentemente ouvirá o uso das palavras “complexo” e “complicado”. Ao usar essas expressões, precisamos ter cuidado para selecionar a que expressa com precisão nossa opinião. Por exemplo, alguém pode dizer que um software é “complicado”, quando na verdade quer dizer que ele é “complexo” (e vice-versa). Infelizmente, a definição dessas duas palavras não ajuda a esclarecer qual delas devemos usar e em que contexto. Isso pode dificultar a expressão do que realmente queremos dizer.
Para mim, descrever algo como sendo “complicado” infere uma conotação negativa (o senhor usou uma lógica ruim ou implementou um projeto ruim). Geralmente, a frase “isso parece ter sido projetado em excesso” vem em seguida.
A palavra “complexidade”, por outro lado, representa para mim um valor variável (na medida em que depende do sistema que está sendo analisado) e, portanto, parece um termo mais apropriado para ser usado quando se reconhece que o design do software evoluiu e se tornou muito maior ao longo do tempo.
O senhor também pode aplicar o termo “complexo” a unidades individuais de código. Se uma classe ou função estiver assumindo muita responsabilidade, pode parecer que está se tornando muito complexa e, consequentemente, parte de sua lógica precisará ser extraída para outra classe ou função. Isso é o oposto de, digamos, uma função que usa um algoritmo ruim, em que o senhor pode identificar esse código como sendo “complicado”.
Agora, se um software tiver muitas partes móveis (a maioria dos aplicativos tem) e o senhor tiver dificuldade em criar um modelo mental de tudo isso e, consequentemente, não conseguir seguir o fio da meada com muita facilidade, isso não significa necessariamente que o aplicativo seja “complicado”. Muitos componentes funcionais pequenos, simples e não complicados podem ser compostos juntos para criar um sistema muito maior e, consequentemente, podem tornar o quadro geral um pouco mais difícil de decifrar. É isso que torna o software “complexo”.
Um bom design de código nem sempre ajuda o senhor a ver o panorama geral. O que um bom design de código ajuda é tornar as unidades funcionais menores muito mais fáceis de entender e compor (por exemplo, SRP – Single Responsibility Principle (Princípio da Responsabilidade Única); uma parte do S.O.L.I.D).
A razão pela qual estou mencionando isso antecipadamente é porque não quero que as pessoas saiam (erroneamente) pensando que o software existente ou sua arquitetura são fundamentalmente falhos ou quebrados. O senhor deve sempre ter um olhar crítico sobre seus sistemas/aplicativos, mas esteja ciente de que, embora eles possam ser “complexos”, essa pode ser a ordem natural das coisas. Uma reescrita completa não é necessariamente necessária.
Com a discussão sobre complexidade encerrada, vamos ver o que significa para o software ser “simples”. Por que a simplicidade é uma coisa boa? A própria simplicidade é definida como:
“a qualidade ou condição de ser fácil de entender ou fazer”.
Se um software for considerado “simples”, é provável que ele tenha sido considerado fácil de entender e de raciocinar. Um software simples também é fácil de manipular e de fazer alterações. Kent Beck (renomado autor de muitos livros de engenharia de software de alta qualidade e cocriador do Extreme Programming, que depois evoluiu para práticas “ágeis”) fez a seguinte declaração em 2012:
“Faça a mudança fácil, depois faça a mudança fácil”
Kent estava se referindo ao fato de que, para que um software fosse facilmente alterado, o senhor precisava simplificar seu design de modo a facilitar uma exigência futura.
A simplicidade também tende a resultar em menos bugs, porque há menos partes móveis complicadas. A ironia de tudo isso é que escrever e projetar código para ser simples geralmente é uma tarefa bastante complexa. É importante perceber que simplicity != easy. Muitas pessoas não conseguem fazer a distinção entre os dois.
A simplicidade também pode (nem sempre, veja o senhor) ajudar a atingir outros objetivos, como a reutilização e a portabilidade do seu software.
Nomeando coisas
Phil Karlton (engenheiro da Netscape; infelizmente morto em 1997) disse uma vez:
Há apenas duas coisas difíceis na ciência da computação: invalidação de cache e nomeação de coisas
É provável que o senhor já tenha ouvido essa citação muitas vezes ao longo de sua carreira. Há uma razão para isso: porque é uma verdade dolorosamente universal. Nada faz com que nossa equipe se sente em um impasse (ou talvez um impasse vivo seja mais preciso) do que quando estamos tentando descobrir como chamar nossa nova biblioteca.
As pessoas subestimam a importância de nomear corretamente as coisas. Seja uma nova biblioteca de código aberto, uma classe, uma função, uma variável (não importa o que seja), há a possibilidade de causar confusão e, em alguns casos, problemas reais se o nome for mal dado.
Há o dilema clássico do front-end em que um desenvolvedor cria uma classe chamada .red-banner porque ela é aplicada a um componente que é, bem, vermelho; e, um mês depois, os designers entram em ação e alteram o componente para que ele tenha um fundo azul. Ótimo, agora isso não parece ser um grande problema, mas aumente o tamanho do site e os possíveis locais em que essa classe é usada; agora, acrescente a isso um pouco mais de ambiguidade e, de repente, o senhor incorreu em uma “dívida tecnológica”.
Esse foi apenas um exemplo superbásico. Na prática, o senhor encontrará problemas de nomenclatura em todos os lugares. O nome da sua classe realmente representa sua intenção? O nome que o senhor usou é muito explícito? Com isso quero dizer que ele faz referência a um tipo de objeto específico ou a um aspecto de design que impede que a classe seja realmente genérica?
Por exemplo, se o senhor tem uma classe que atua como mediadora entre dois objetos, o senhor a nomeou “MessageBus” porque está usando atualmente o padrão Observer/PubSub? E se a classe mudar de funcionalidade para algum outro padrão ou software? Certamente, o senhor a nomeou para ser ComponentMediator seria melhor, pois isso é claro o suficiente para expressar a intenção da classe e, ao mesmo tempo, aberto o suficiente para que os detalhes da implementação sejam alterados no futuro (como uma espécie de Princípio aberto/fechado).
De qualquer forma, o senhor não deve subestimar os problemas e a confusão que podem ser causados por um objeto/classe/coisa mal nomeado. Fique atento e, se não tiver certeza, discuta o assunto com sua equipe. Mas atenção, esse nem sempre é um processo rápido ou óbvio.
Crescimento
Os aplicativos são orgânicos; eles crescem e evoluem com o tempo, o que pode aumentar sua complexidade. Mas o software também precisa lidar com a crescente popularidade, o que significa maior tráfego e a necessidade de estar sempre disponível (ou seja, em funcionamento!). Todo software deve ter um mínimo de escalabilidade em mente nos estágios de projeto. Seria tolice não considerar, pelo menos, o que acontece quando o sistema é submetido a uma carga pesada.
A BBC tem equipes específicas de plataforma dedicadas à realização de testes de carga antes de qualquer lançamento importante de software. A vantagem disso é garantir que um novo software possa ser executado com segurança ao lidar com um número x de solicitações por segundo. Os resultados dos testes de carga ajudam a indicar qual será o limite de um aplicativo.
Minha equipe normalmente usa uma ferramenta de linha de comando chamada Siege para testar nossos aplicativos antes de solicitar um teste de carga completo à nossa equipe de plataforma, pois isso pode ajudar a eliminar erros bobos antes de passar pelos canais oficiais.
A BBC também utiliza Macaco do Caos (uma ferramenta desenvolvida pela Netflix) para ajudar a verificar a resiliência de seus sistemas. O próprio Chaos Monkey tem sido fundamental para a forma como começamos a olhar para o design e a arquitetura de nossos sistemas e aplicativos.
O objetivo do Chaos Monkey é derrubar (aleatoriamente) uma instância de servidor que esteja em execução no momento. Isso parece uma coisa maluca de se fazer em seu ambiente de produção, mas a realidade é que isso o obriga a pensar bastante na fase de design de seus aplicativos para garantir que eles sejam resilientes e capazes de serem recuperados automaticamente.
A qualquer momento, o Chaos Monkey poderia derrubar um de nossos servidores que executam um aplicativo público e altamente crítico. Isso ajuda a perceber que o senhor precisa começar a considerar soluções antes de escrever qualquer código. Ao realmente pensar no design com antecedência, o senhor evita problemas em que pode descobrir que o software existente simplesmente não é resiliente o suficiente e causará interrupções inaceitáveis no serviço; e, ainda assim, o sistema existente pode estar em um estado tal que não facilite um caminho fácil para se tornar escalável (por exemplo, um aplicativo monolítico com muitas responsabilidades e áreas de domínio introduzirá um ponto único de falha maciço e levará muito tempo para ser refatorado).
As soluções para o problema de resiliência e escalabilidade (no estágio de design) poderiam, por exemplo, envolver a criação de microsserviços para ajudar a isolar pontos únicos de falha. Assim como a implementação de servidores sem estado/imutáveis, em que o senhor pode abrir uma nova instância sem se preocupar com a perda de um estado crítico (juntamente com mecanismos de descoberta de serviços, como o Consul ou etcd). A infraestrutura como código é outro conceito importante e pode ser obtida usando tecnologias como AWS CloudFormation (que discutiremos em mais detalhes posteriormente neste post).
O dimensionamento de um sistema para acomodar mais usuários não é um almoço grátis; isso pode causar a introdução de uma complexidade inerente, pois é necessário considerar muitos mecanismos diferentes para facilitar o aumento do tráfego.
Normalmente, a primeira coisa que os desenvolvedores fazem (antes de considerar mudanças arquitetônicas mais extremas) é tentar executar seu código em paralelo (ou suportar mais operações simultâneas). Não há nada necessariamente errado com isso, a menos que seu código não seja “seguro para threads“. A correção do problema de segurança de thread nem sempre é simples e, se o conceito de código com vários threads for novo para o usuário, é provável que ele encontre alguns obstáculos à medida que começa a entender lentamente o espaço do problema.
Se o senhor estiver interessado em entender a segurança de thread (e as diferentes abstrações de simultaneidade) em mais detalhes, recomendo que leia o seguinte artigo “Concorrência segura de thread“.
Juntamente com o processo de tentar acelerar o código por meio de multi-threading, o senhor quase sempre desejará que seu aplicativo seja dimensionado automaticamente com base nas necessidades atuais do sistema. Se o aplicativo estiver sendo executado em uma infraestrutura projetada para ser dimensionada “horizontalmente” (por exemplo, ela cria dinamicamente novas instâncias de servidor que executam o aplicativo), o problema da consistência dos dados começará a surgir rapidamente.
A consistência dos dados é onde o “teorema CAP” entra em ação. O CAP afirma:
“é impossível que um sistema de computador distribuído forneça simultaneamente todas as três garantias a seguir: consistência, disponibilidade e tolerância a partições”
O que isso significa na prática é:
- Consistência: todos os nós do seu sistema devem ter a mesma visão do mundo
- Disponibilidade: uma resposta garantida (seja uma mensagem de sucesso ou de falha)
- Tolerância de partição: o sistema como um todo continua funcionando mesmo quando uma parte do sistema falha completamente (ou as mensagens entre sistemas desacoplados são perdidas)
O problema do crescimento também pode afetar as decisões tomadas a partir das perspectivas de desenvolvimento back-end e front-end. Por exemplo, ao criar aplicativos de processamento de dados em tempo real, o senhor tem a opção de fazer polling longo e lidar com a contrapressão versus Web Sockets versus eventos enviados pelo servidor; tudo isso com suporte variável ao navegador, e cada uma dessas opções abre um conjunto diferente de preocupações com relação à arquitetura do sistema back-end.
O problema de crescimento e dimensionamento de aplicativos pode ser simplificado com a divisão do seu aplicativo em unidades funcionais bem definidas e isoladas. Se o senhor estiver trabalhando com um único aplicativo monolítico, tente imaginar como ele seria se fosse dividido em vários serviços isolados. Onde cada parte do aplicativo se comunicasse com outro serviço via HTTP (ou TCP, ou por meio de algum outro mecanismo de baixo nível). Qual seria a aparência do sistema? O senhor não acha que seria mais fácil analisar e dimensionar serviços individuais do que um aplicativo monolítico enorme?
Isso nos leva muito bem ao tópico de “Microsserviços”…
A micro falácia?
A partir de 2014/2015, os microsserviços são uma palavra da moda. Muitas organizações e empresas estão falando sobre projetar microsserviços e usar ferramentas (como Docker) para permitir que eles criem e dimensionem mais facilmente seu crescente conjunto de microsserviços.
Achei importante fazer uma rápida menção ao fato de que as pessoas tendem a ver um aplicativo monolítico como ruim e um sistema de pequenos serviços como bom. Embora eu tenda a concordar, gostaria de dizer que já estive em ambos os lados da cerca e cada um tem seus prós e contras. Se o senhor estiver trabalhando em um sistema de pequena escala, um projeto de microsserviço pode representar uma sobrecarga extra e uma complexidade desnecessária de que não precisa. Só porque todas as crianças descoladas estão bebendo o koolaid dos microsserviços, não significa que o senhor tenha (ou deva) fazê-lo. Sempre tenha um olhar crítico sobre seu projeto e avalie as coisas com base em sua própria situação/requisitos.
Dito isso, eu pessoalmente vejo os microsserviços como a forma como projetaremos e construiremos em grande escala pois, no geral, ele oferece muito mais benefícios em comparação com os aplicativos monolíticos da velha guarda. Ao projetar serviços, é importante que o senhor divida adequadamente as responsabilidades no aplicativo e tente encontrar um ponto ideal entre a separação de preocupações e domínios e a fragmentação.
Sistemas de desacoplamento
Ao considerarmos o projeto de um sistema complexo, o ideal é que separemos nosso código por áreas de domínio individuais. O motivo é que isso nos permite escalonar qualquer parte específica do sistema que se torne um gargalo, em vez de realizar um escalonamento geral de todo o sistema, o que não é apenas caro, mas também impraticável.
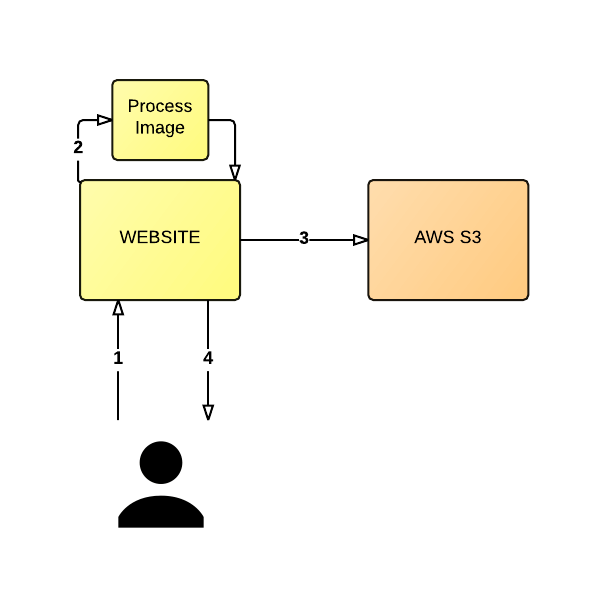
Usando o diagrama a seguir como base, vamos considerar um aplicativo em que o usuário faz upload de uma imagem (1) e o servidor redimensiona a imagem (2) e coloca a imagem recém-criada em um AWS S3 (3). Espera-se que o servidor retorne um URL gerado automaticamente para o usuário (4), que, quando compartilhado e visitado por outro usuário, mostrará a imagem redimensionada.
Essa arquitetura não será dimensionada muito bem, nem muito facilmente.
Observação: para ser breve, deixei de fora alguns detalhes dessa arquitetura, como a persistência de URLs
Em vez disso, o processo deve ser mais desacoplado, da seguinte forma (veja o diagrama abaixo): o usuário faz upload de uma imagem (1), o servidor armazena a imagem em um bucket S3 em sua forma original (2) e envia uma mensagem para um AWS SQS fila (3). Em seguida, o servidor retorna uma mensagem ao usuário para informá-lo de que a imagem está sendo processada juntamente com o URL gerado automaticamente (4).
Nesse meio tempo, um serviço separado está pesquisando a fila de mensagens (5). O serviço lerá a mensagem (que pode incluir o local da imagem de origem no S3) e, em seguida, recuperará a imagem relevante do S3 (6) para que possa redimensionar a imagem (7) e substituir a imagem no S3 pela versão redimensionada (8), ou o que for necessário nesse momento.
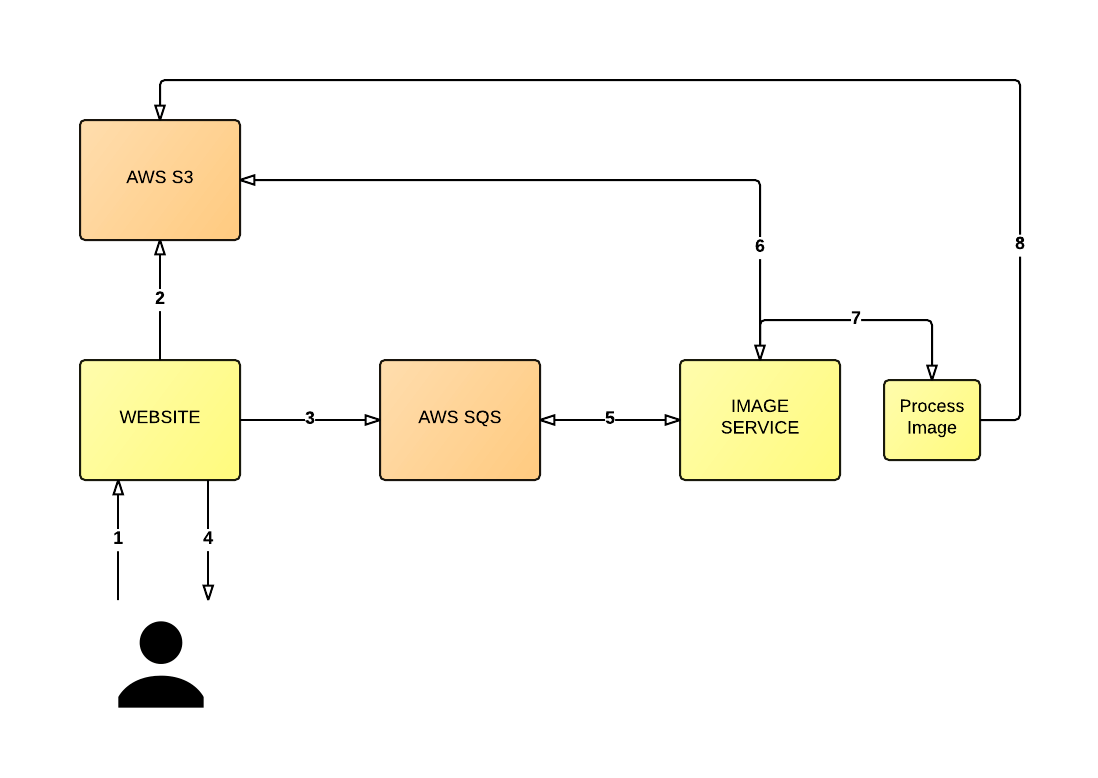
Portanto, esse design pode não ser perfeito, mas o que há de melhor nessa arquitetura é que desacoplamos as várias partes do sistema geral que, anteriormente, teriam dificultado muito o dimensionamento do aplicativo. Agora estamos em condições de dimensionar o serviço de back-end (o serviço que pesquisa a fila e redimensiona as imagens) separadamente do sistema de front-end que lida com o upload do usuário.
Se o usuário visitar o URL gerado automaticamente antes de a imagem ter sido processada, uma mensagem poderá ser exibida para indicar que a imagem ainda está sendo processada. Mais uma vez, isso não é perfeito, mas libera o usuário para fazer outras coisas, pois ele não fica preso à janela do navegador observando uma mensagem que diz “Processing…” (Processando…) pelos próximos minutos (ou mais, dependendo da carga do sistema).
Uma melhoria prática aqui é que o novo sistema é muito mais tolerante a falhas do que o original. No sistema original, se o servidor falhasse, o usuário provavelmente receberia um Código de status HTTP 500e, com o novo sistema, o usuário pode continuar a usar o site (ele verá a mensagem “Image waiting to be processed” (Imagem aguardando processamento) até que uma nova instância de servidor back-end possa ser ativada, onde ele continuará a processar as mensagens da fila de imagens).
Observação: a tolerância a falhas é frequentemente chamada de “tolerância a partições”; mencionei isso anteriormente ao discutir o Teorema CAP.
No exemplo acima, usamos filas para ajudar a desacoplar as partes individuais do nosso sistema de software (semelhante em espírito à criação de microsserviços), mas há outros mecanismos para desacoplar o código, como o uso de um barramento de mensagens. É melhor pesquisar técnicas diferentes para ver como sua arquitetura pode ser projetada para utilizá-las e evitar problemas de escalonamento.
Observação: dependendo da finalidade do aplicativo acima, o senhor pode decidir que exibir a imagem não otimizada seria melhor do que exibir uma mensagem para o usuário informando que a imagem ainda está sendo processada. A razão pela qual não fiz isso aqui foi por motivos de desempenho (o tamanho da imagem pode ser muito grande e não é algo que o senhor queira que um usuário móvel tenha que baixar, especialmente se ele estiver viajando com uma conexão de rede ruim)
Corretor/Remetente
Na BBC News de Londres, minha equipe lançou uma estrutura de código aberto escrita em Ruby chamada Alephantque abstrai um padrão comum que consideramos útil para desacoplar nossos aplicativos orientados por dados.
Usamos essa estrutura específica em vários projetos ao longo do último ano e meio, como o referendo escocês, as eleições locais e gerais, um futuro redesenho da BBC Newsbeat e o projeto World Service Kaleidoscope (veiculação dinâmica de conteúdo baseado em imagens para dispositivos com suporte insuficiente para fontes não latinas).
Observação: Gostaria de fazer um agradecimento ao Robert Kenny (ex-BBC e atualmente trabalhando no Guardian) foi a inspiração original e o desenvolvedor da estrutura Alephant. Embora tenha mudado significativamente desde sua criação, foi seu trabalho sólido que ajudou a apoiar alguns eventos muito importantes e de alto tráfego.
O padrão é efetivamente um “corretor” (ou seja, mediador) e um “renderizador”. Com esse padrão, as solicitações dos usuários são encaminhadas para o corretor relevante, que decide para onde as solicitações devem ser direcionadas. Na outra extremidade do projeto, há vários serviços de “renderização”, e sua função muda dependendo do tipo de modelo que usamos: push ou pull.
Vamos explorar isso um pouco mais:
- Corretor: um serviço que aceita solicitações (as solicitações são tratadas de forma diferente dependendo do modelo)
- Renderizador: um serviço que obtém dados de um endpoint e os renderiza em HTML (ou em qualquer formato necessário)
- Modelos: “push” e “pull” (veremos o que é cada um deles na próxima seção)
Empurrar
O modelo push é semelhante à arquitetura de “processamento de imagens” que discutimos na seção anterior, pois estamos usando uma fila para desacoplar nossos serviços.
No modelo push, as mensagens são colocadas em uma fila. Essas mensagens contêm dados que queremos que sejam renderizados em HTML (para usar um cenário do mundo real: os resultados das eleições são colocados em uma fila). Em seguida, temos um serviço de renderização em execução e esse serviço pesquisa as mensagens na fila. Quando uma mensagem (por exemplo, o resultado da eleição) é recebida, processamos essa mensagem, a transformamos em HTML e armazenamos esse conteúdo transformado em uma área de armazenamento (que pode ser qualquer sistema de armazenamento baseado em nuvem, como o AWS S3, por exemplo).
O serviço de renderização é facilmente dimensionável porque podemos definir limites de alarme que indicam se há muitas mensagens em uma fila (ou seja, se houver muitas mensagens aguardando na fila, então nosso serviço de renderização não está processando-as com rapidez suficiente e, portanto, precisamos dimensionar mais instâncias de renderização para lidar com a carga de mensagens).
O AWS SQS não garante uma ordem de entrega (isso não é verdade para todas as filas, portanto, se a ordem de entrega for importante para o senhor, há outros tipos de filas disponíveis) e, portanto, é preciso tomar cuidado para garantir que as mensagens não sejam sobrescritas. Descobrimos que esse tipo de contenção poderia ocorrer ao dimensionar nosso serviço Renderer.
Para dar um exemplo ao senhor, imagine que temos dois Renderers: R1 e R2. Ambos retiram uma mensagem da fila. R1 recebe a versão 1 da mensagem “A”, enquanto R2 recebe a versão 2 atualizada da mensagem “A”. Se R2 terminar primeiro, então R1 terminará por último e, posteriormente, a versão mais antiga da mensagem será armazenada e usada (um exemplo real e prático disso é a obtenção de resultados eleitorais em uma fila; a contagem de votos de um determinado partido precisa ser a mais recente).
Para evitar essa contenção, usamos um armazenamento de documentos (AWS DynamoDB) para rastrear a versão de uma mensagem e, quando armazenamos o conteúdo renderizado de nossos dados em nossa instalação de armazenamento, garantimos que a chave necessária para pesquisar esse conteúdo renderizado também inclua seu número de versão.
Observação: isso é algo que fizemos antes de o DynamoDB adicionar o recurso “Conditional Put”
O corretor no modelo push recebe uma solicitação de um componente e é capaz de usar as informações fornecidas para procurar a última versão renderizada de uma mensagem. Ele faz isso criando uma chave que determina o local da versão mais recente em nossa instalação de armazenamento. Essas pesquisas também são altamente armazenadas em cache para que possamos lidar com o máximo de carga possível.
O diagrama a seguir oferece ao senhor uma visão de nível superior dessa arquitetura:
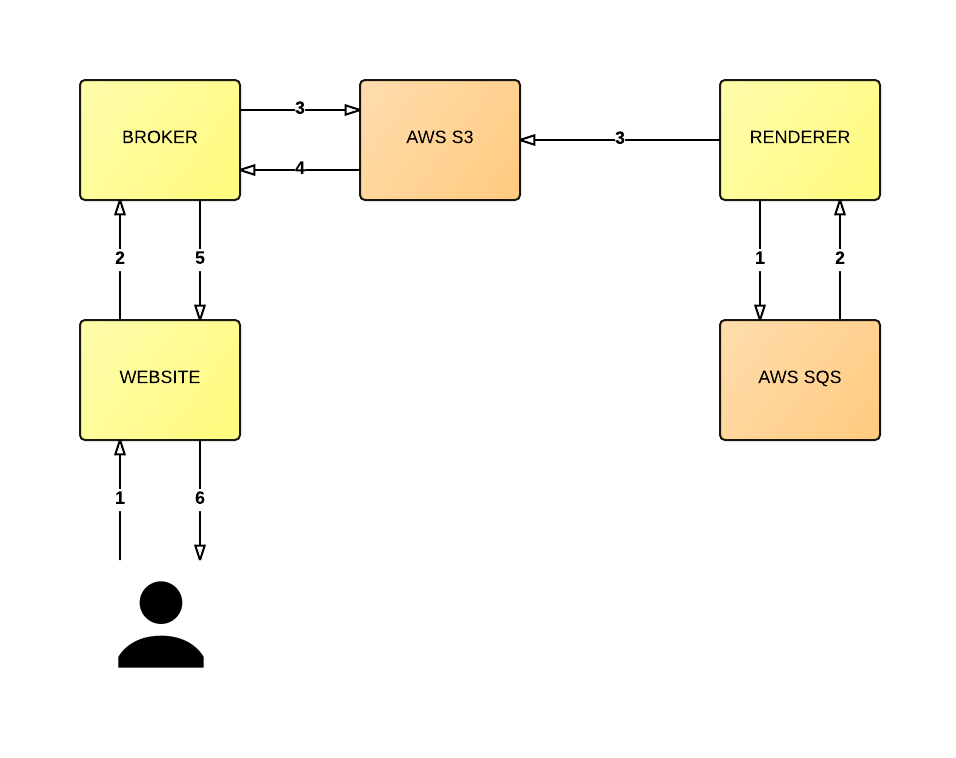
Observação: para ser breve, no diagrama acima, não estou demonstrando o armazenamento em cache das solicitações do broker nem os requisitos de sequenciamento (ou seja, o armazenamento da versão de uma mensagem no DynamoDB). Conforme mencionado anteriormente, algumas filas têm garantias diferentes e, por isso, não queria que o diagrama fosse muito ligado à implementação do DynamoDB
Há outra preocupação que levamos em conta, mas que deixei de fora por questões de brevidade, que é o modelo de “consistência eventual” do AWS S3. Mas acho que, por enquanto, essa explicação deve ser suficiente para dar ao senhor uma ideia de como o padrão funciona.
Puxar
O modelo pull é mais simples, pois não depende de uma fila de mensagens para seus dados. Nesse modelo, nossos renderizadores estão mais “conectados” ao nosso corretor.
Quero dizer com isso que o corretor receberá uma solicitação de um componente e usará as informações que foram passadas com a solicitação para procurar o renderizador relevante com o qual precisa entrar em contato (descoberta de serviço), a fim de recuperar o componente solicitado. O serviço de renderização tem um ponto de extremidade remoto incorporado, que ele usa para fazer solicitações, a fim de recuperar os dados necessários para que uma renderização bem-sucedida ocorra (portanto, não há armazenamento de componentes renderizados em uma instalação de armazenamento; estamos renderizando dinamicamente os dados mediante solicitação).
O motivo pelo qual criamos esse modelo foi porque tínhamos determinados modelos de domínio em que as alterações de dados eram vastas e exigiriam uma grande quantidade de renderização inicial que talvez nunca fosse vista (ou seja, solicitada) por um usuário final. As páginas Market Data da BBC eram um exemplo disso, em que alguns dados comerciais raramente eram visualizados.)
O diagrama a seguir oferece ao senhor uma visão de nível superior dessa arquitetura:
Observação: para ser breve, no diagrama acima, não estou detalhando a complexidade de como o senhor fornece informações a um broker para que ele saiba qual renderizador interrogar para atender à solicitação do usuário
No entanto, há algumas armadilhas nesse modelo. A principal delas é que estamos acoplando nossos dados aos nossos modelos. Por exemplo, se for necessária uma alteração no modelo (digamos, um HTML class seja adicionado a um elemento, mas toda a outra “estrutura” do conteúdo seja a mesma), isso exigiria uma nova renderização completa do componente.
Fizemos experiências (breves) com a renderização dos dados em si e, em seguida, deixamos que uma camada mais a jusante tratasse da composição do modelo, mas isso resultou em outras complicações. Com prazos iminentes e preocupações com relação a forçar a responsabilidade pelos modelos em alguma outra parte do sistema, decidimos adiar.
Design e arquitetura
A razão pela qual consideramos o padrão broker/renderer tão útil é a forma como projetamos as bibliotecas individuais que compõem a estrutura. Elas permitem que os consumidores das bibliotecas forneçam configuração personalizada para atender a seus próprios requisitos específicos. Também usamos o padrão de design de estratégia para o modelo pull, que permite que um aplicativo consumidor injete a lógica que a biblioteca deve usar para determinar como construir endpoints de dados remotos (caso o caminho do local de armazenamento seja diferente para sua configuração).
Essa é a essência da capacidade de composição, é como se os tijolos de lego se encaixassem para formar uma peça grande. Embora o senhor possa utilizar aspectos individuais das estruturas que atendam às suas necessidades (porque cada biblioteca é autossuficiente no fornecimento de funcionalidades isoladas), a estrutura funciona melhor quando utilizada para formar o padrão de corretor/renderizador para o qual projetamos a estrutura.
É uma mistura interessante de SRP (Single Responsibility Principle, princípio da responsabilidade única) e a capacidade de composição da FP (Functional Programming, programação funcional).
Quão baixo o senhor pode (ou deve) ir?
Para qualquer aplicativo de desempenho crítico (e dimensionável), é importante considerar a sobrecarga de determinadas tecnologias. Por exemplo, quando se tratou de criar a estrutura do Alephant (discutida na seção anterior), decidimos que Sinatra (uma estrutura web Ruby muito popular que é preferível a uma estrutura monolítica como a Ruby on Rails) ainda era muito volumoso para nossas necessidades.
Com isso quero dizer que ele tinha todos os tipos de recursos relacionados à Web de que não precisávamos para nosso aplicativo. Por isso, optamos pela interface Rack de nível inferior (quase, mas não totalmente, bare metal). Dependendo dos seus requisitos, pode até valer a pena considerar a possibilidade de descer um nível do HTTP para o TCP ou até mesmo para os protocolos de soquete UDP se realmente não precisar da sobrecarga extra do HTTP para a comunicação entre os serviços (por exemplo, você pode ter serviços internos em execução nas instâncias do servidor que não são expostos publicamente).
É importante perceber que remover as camadas de complexidade pode ajudar a revelar melhor a intenção do seu código. Tornando-o mais fácil de entender e de raciocinar.
Modelos independentes de idioma
Na BBC, descobrimos (da maneira mais difícil) que nossa abordagem para gerenciar o armazenamento e a implementação de componentes de front-end não era dimensionável. O problema era decorrente de um método mais tradicional de estruturação de aplicativos de front-end, o que significava separar JavaScript, CSS e imagens em pastas distintas.
Por enquanto, vamos considerar a pasta JavaScript: dentro dessa pasta, teríamos vários “módulos” (um módulo é um único arquivo JavaScript e representa uma parte isolada da funcionalidade). Um único componente HTML poderia muito bem ter vários requisitos funcionais, o que significa que ele dependeria de vários módulos JavaScript.
Isso não deve parecer estranho para ninguém, pois a maioria dos desenvolvedores separa suas preocupações dessa forma. No entanto, a desvantagem dessa abordagem é que, quando o sistema começar a se expandir e evoluir, o senhor começará a perceber o problema da fragmentação e do forte acoplamento dos componentes ao aplicativo. atualmente reside dentro.
Com isso quero dizer: se o senhor tem um componente HTML e ele depende dos módulos JavaScript X e Y, bem como dos arquivos CSS A e B, não é possível reutilizar facilmente esse componente em outro sistema sem replicar a estrutura de diretórios que o aplicativo atual utiliza ou fazer alterações no código para refletir o local das dependências no novo sistema. Além disso, a árvore de dependência de cada componente estava ficando maior e mais difícil de visualizar e manter (à medida que mais e mais funcionalidades eram adicionadas a determinados componentes).
Nesse modelo arquitetônico clássico, o senhor perde (ou pelo menos complica) a capacidade de manutenção, a reutilização, a portabilidade e até mesmo a capacidade de isolar componentes para facilitar os testes. A capacidade de compartilhar componentes entre equipes (que trabalham em plataformas diferentes) também estava se mostrando difícil, pois estávamos sendo forçados a duplicar o conteúdo, o que levou à decisão de criar uma especificação que descrevesse como criar componentes verdadeiramente atômicos que pudessem ser facilmente consumidos por serviços variados.
Entre Peter Chamberlin e Liam Wilkins para se inspirar em ambos Design atômico de Brad Frost e Rizzo de Ian Feather e ajudou a resolver essa divisão ao criar o projeto de código aberto “Chintz“, que combina os melhores aspectos de ambos os projetos anteriores.
Observação: este projeto ainda é WIP (work in progress, trabalho em andamento), mas incentivamos a comunidade a se envolver e criar uma discussão aberta sobre como a especificação evolui
A força motriz por trás dessa especificação era que ela fosse independente de idioma. Esse foi um requisito fundamental para permitir que plataformas de idiomas diferentes consumissem esses componentes. O processamento de componentes tem alguns requisitos simples:
- definir uma estrutura de pastas que conterá os componentes
- definir um manifesto que descreva as dependências de um determinado componente
- implementar um analisador de cliente que resolva as dependências dentro do manifesto
- criar um aplicativo que consuma o analisador do cliente
No diagrama a seguir, mostramos como duas plataformas separadas (PHP e Ruby) consomem um analisador específico de sua linguagem para resolver as dependências de um determinado componente e apresentar o(s) componente(s) da maneira mais apropriada para sua plataforma:
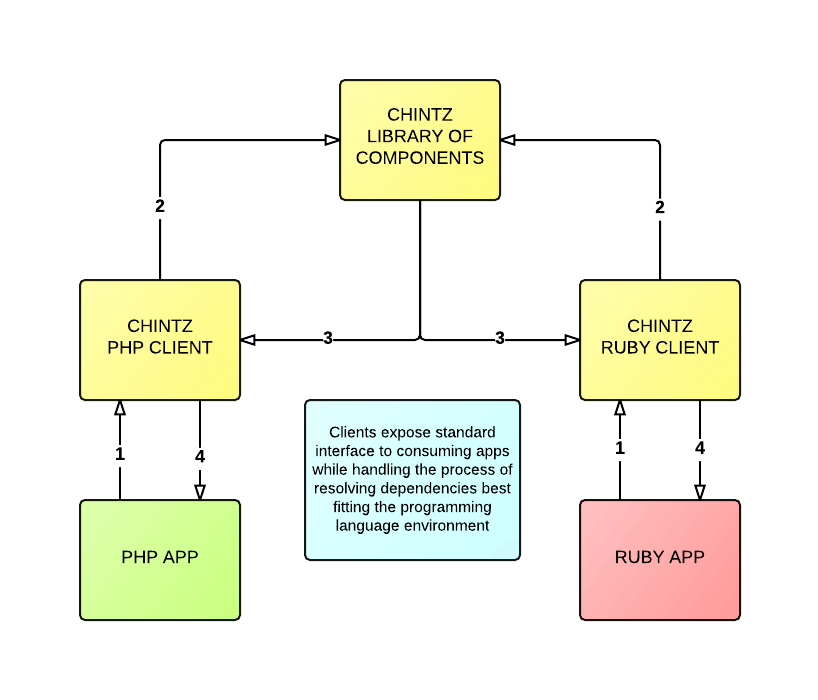
No momento, há dois analisadores de cliente (WIP) cujo código aberto é nosso:
Observação: também esperamos implementar um utilizando JavaScript/Node
Um arquivo de manifesto pode se parecer com algo como:
name: exampleElement dependencies: css: [ base/base.css, base/typography.css ] js: [ exampleElement/someOtherFilename.js ] elements: [ anotherThing ]
Esse arquivo de manifesto simplifica a compreensão da complexidade de um único componente.
A esperança é que, no futuro, nossa biblioteca interna de padrões de componentes, criada com base no Chintz, seja utilizada pelas equipes que trabalham em diferentes plataformas. Por exemplo, a equipe principal da BBC News trabalha em uma plataforma PHP tradicional, enquanto a equipe da Elections Presentation desenvolve componentes baseados em nuvem (gerados com Ruby) que são consumidos pela plataforma da equipe principal.
Automação e duplicação
Ao lidar com grandes sistemas de software, o senhor precisará garantir que está automatizando as coisas e reduzindo a quantidade de trabalho repetitivo que tem. Isso é essencial ao gerenciar software de qualquer escala substancial.
Há algumas maneiras pelas quais minha equipe automatiza e reduz a duplicação (o senhor provavelmente encontrará conceitos e processos semelhantes em muitas outras equipes e produtos):
- Entrega contínua
- AWS CloudFormation
- Abstrações de bibliotecas personalizadas
- Containerização via Docker
Entrega contínua
A implementação de software na BBC pode ser um processo complexo, pois temos muitas partes móveis para transformar o código do laptop de um desenvolvedor em uma versão funcional que é implementada em nossa infraestrutura de nuvem. Para tornar a implementação de software o mais simples possível, desenvolvemos um complicado pipeline de implementação para tentar ajudar a atingir o objetivo final de ter um processo de lançamento “simples”.
Observe que eu disse “complicado” 🙁
Atualmente, usamos o Jenkins servidor de integração contínua para dar suporte ao nosso processo de implementação. O Jenkins é um software padrão do setor e nenhuma organização deveria estar lançando software sem alguma forma de CI.
Quando enviamos o código para o GitHub, acionamos um trabalho de compilação no Jenkins que cria um RPM que desejamos implantar em nossos servidores de nuvem distribuídos. Mas antes que a implementação possa acontecer, precisamos ter certeza de que nosso software é seguro para ser lançado. Isso significa que acionamos outro trabalho que verifica isso por meio de diferentes testes de unidade e integração para nosso ambiente de integração.
Se tudo estiver bem, acionamos o próximo conjunto de trabalhos que fazem o mesmo para o nosso ambiente de teste e, mais uma vez, para o nosso ambiente ativo. Se qualquer um desses trabalhos falhar, a implementação nesse ambiente será marcada como falha.
Agora, o motivo pelo qual usei a palavra “complicado” anteriormente (em vez da palavra “complexo”, mais ideal – consulte o início desta postagem do blog para saber a diferença entre elas) é porque, fundamentalmente, atingimos os limites do que o software Jenkins pode suportar e isso resultou em uma solução que pode funcionar (na maior parte do tempo), mas é complicada demais para ser mantida. Se uma compilação quebrar, pode ser muito difícil seguir o rastro porque o Jenkins não foi realmente projetado com a Entrega Contínua em mente.
Embora o Jenkins forneça plug-ins para ajudar a ampliar sua funcionalidade, de modo que possa suportar processos de pipeline de implantação mais complexos, as várias opções de plug-ins disponíveis não são tão boas quanto poderiam ser, e a maioria não oferece uma visibilidade clara do status de um determinado grupo de trabalhos. É nesse ponto que algo como o GOCDque visa a simplificar o ciclo de vida de construção-teste-lançamento, entraria na equação.
O Jenkins cumpriu seu propósito e descobrimos que ele não é mais um software complexo, mas passou a ser mais complicado. Se o senhor se encontrar em uma situação semelhante, isso deve ser uma indicação de que precisa monitorar constantemente seus processos e avaliar sua eficácia.
Nossa configuração Jenkins funciona, portanto, é “boa o suficiente” no momento. Mas não caia na armadilha de aceitar o sistema atual como sendo “bom o suficiente”. No momento em que começar a sentir dor ao configurar ou implementar um software, assim como um bom cheiro de código indica a necessidade de refatoração, o senhor deve começar a reavaliar como a situação pode ser melhorada. Isso é algo que estamos fazendo ativamente no momento.
Lembre-se de não tomar nenhuma decisão precipitada (por exemplo, vamos implementar um sistema de CI/CD totalmente novo) que possa potencialmente deixá-lo com mais dívidas tecnológicas do que você percebeu inicialmente, especialmente se a sua equipe já tiver prazos muito apertados. Aumentar a carga de trabalho não é uma decisão sensata. Alterar o processo de implementação é uma decisão extremamente importante e, portanto, o senhor deve ter certeza absoluta de que esgotou todas as outras opções primeiro.
AWS CloudFormation
Se o senhor não estiver familiarizado com o CloudFormation, vou encaminhá-lo para a definição oficial:
O AWS CloudFormation oferece aos desenvolvedores e administradores de sistemas uma maneira fácil de criar e gerenciar uma coleção de recursos relacionados da AWS, provisionando-os e atualizando-os de forma ordenada e previsível
O AWS CloudFormation é excelente por dois motivos principais:
- Ele automatiza a capacidade de iniciar e provisionar uma infraestrutura consistente e reproduzível
- Facilita a capacidade de controlar a versão de sua infraestrutura
Com relação ao primeiro ponto, isso também facilita a configuração perfeita de diferentes ambientes de implementação. Isso significa que podemos configurar cada ambiente específico (usando parâmetros do CloudFormation) para permitir, por exemplo, que os ambientes de integração e teste tenham instâncias de servidor EC2 muito pequenas, enquanto os ambientes de estágio e produção têm instâncias de servidor maiores (ajudando a manter os custos baixos em nossos ambientes não críticos, como integração e teste).
Dependendo da sua experiência com a AWS, o senhor pode achar que o CloudFormation se enquadra na categoria “complicado”. No entanto, essa é uma opinião muito subjetiva, pois aprender o CloudFormation pode parecer (inicialmente) bastante confuso e complicado; o resultado final é uma maneira muito mais simples, rápida e fácil de criar/automatizar um sistema totalmente provisionado.
Também há ferramentas disponíveis que podem ajudar a facilitar a gravação do CloudFormation bruto (que é apenas um arquivo JSON). O senhor poderia subir um nível de abstração e começar a escrever pilhas de CloudFormation usando YAML ou o senhor pode usar uma DSL específica da linguagem, como CFNDSL (que é uma DSL Ruby).
Abstrações de bibliotecas personalizadas
A maioria dos nossos projetos é construída a partir de uma linha de base de bibliotecas abstratas/genéricas (RPMs) que nos fornecem uma funcionalidade padrão específica. Essas abstrações facilitam muito a construção de uma pilha de software complexa sem a necessidade de nos repetirmos constantemente.
Por exemplo, considere as três bibliotecas a seguir:
- Base de componentes
- Aplicativo JRuby
- Puma Init
Cada uma dessas bibliotecas adicionará seu próprio “perfil” ao /home/component. Cada biblioteca carregará seu perfil, que adicionará um gancho para ser utilizado por outra biblioteca que consome downstream.
Por exemplo…
- Base de componentes: creates
/home/component/.bash_profile - O perfil tenta obter
/home/component/.custom_profile - Aplicativo JRuby: cria
/home/component/.custom_profile - O perfil tenta obter
/home/component/.component_profile - Puma Init: cria
/home/component/.component_profile - O perfil tenta obter
/home/component/.puma_profile
Isso permite que nossas bibliotecas funcionem de maneira semelhante à do Padrão de método de modeloonde as camadas herdadas subsequentes podem adicionar seu próprio comportamento enquanto substituem a configuração upstream específica.
Além dos arquivos de perfil acima, cada biblioteca acrescenta seus próprios comportamentos adicionais. Por exemplo, a primeira biblioteca “Component Base” também configura os seguintes itens:
- a
componentconta de usuário - configura a instância do servidor para utilizar nosso serviço de registro personalizado
- define um
/appcom todas as permissões corretas - define um script de inicialização que executa um daemon (definido via
APP_DAEMON) APP_DAEMONpode ser substituído por uma biblioteca upstream
A segunda biblioteca “JRuby Application” (Aplicativo JRuby):
- carrega o “Component Base” como uma dependência
- e, em seguida, carrega o binário JRuby
Isso significa que um serviço que utiliza a biblioteca “JRuby Application” pode desenvolver um aplicativo voltado para o usuário (por exemplo, que tenha um serviço da Web exposto) ou um aplicativo interno que faça o processamento de dados. Cabe ao desenvolvedor decidir o que construir.
A terceira biblioteca “Puma Init”:
- carrega o “Aplicativo JRuby” como uma dependência
- cria um
/home/component/.component_profilearquivo - isso adiciona a configuração específica do Puma (e substitui o
APP_DAEMONpara fazer referência ao Puma)
Puma é um popular servidor da Web Ruby multi-threaded
O diagrama a seguir fornece uma visualização básica das camadas herdadas:
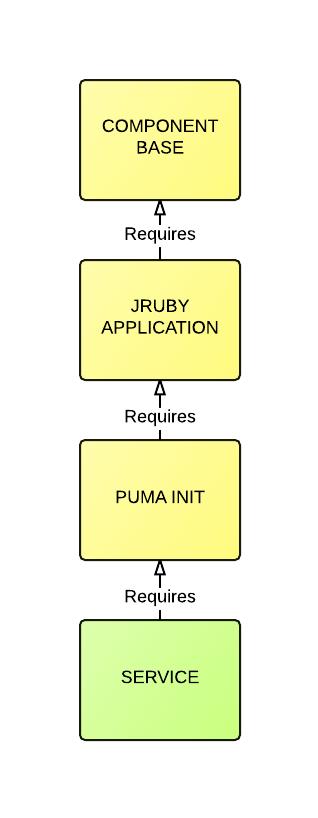
Cada biblioteca atua como uma camada que se baseia na anterior e fornece uma funcionalidade específica que amplia o comportamento geral.
Docker
É bem provável que o senhor já tenha ouvido falar sobre o Docker e a conteinerização. O simples fato é que usamos o Docker porque ele ajuda a manter os aplicativos pequenos, focados (pense no “Princípio da Responsabilidade Única”) e, o mais importante, “isolados” (pense no “código de desacoplamento”).
O Docker também ajuda a facilitar muito a instalação de softwares específicos de baixo nível, com a comunicação padronizada entre contêineres em execução, ajudando esses serviços a interagir.
Usamos o Docker em uma variedade de situações diferentes:
- Integração contínua (usando uma configuração padrão de mestre/escravo e cada trabalho de compilação é seu próprio contêiner)
- Prototipagem (super rápido para começar a usar o novo software)
- Soluções de monitoramento e registro
- Ferramentas (por exemplo, o Espúrios – consulte a seção a seguir – é construído usando contêineres Docker)
Tudo isso dito: O Docker não é uma panaceia. Ele não atende a todos os requisitos do projeto e, em alguns casos, não é a solução certa. Como em todas as coisas, considere os prós e os contras e use-o onde e quando for apropriado.
As ferramentas que o senhor utiliza durante (e após) o desenvolvimento podem ser fundamentais para o sucesso do seu projeto. Não vou abordar todas as várias soluções de ferramentas que temos (pois são muitas), mas quero me concentrar em uma ferramenta em particular: Spurious.
O que o Spurious oferece é um conjunto de serviços da AWS que o senhor pode executar localmente (ou seja, sem lhe custar nada).
Os serviços da AWS com os quais ele trabalha atualmente (CloudFormation e SNS serão lançados em algum momento no futuro):
Atualmente, há bibliotecas auxiliares que configuram o AWS SDK para utilizar o Spurious (fazendo uma integração quase perfeita com o código do seu aplicativo). Essas bibliotecas suportam Ruby, Clojure e JavaScript
Isso, por si só, já é muito útil. Podemos ativar uma instância do Spurious em nossa máquina e começar a escrever o código do aplicativo que interage com uma fila (SQS), um armazenamento de registros (DynamoDB) e um armazenamento de dados (S3), juntamente com solicitações de cache (via ElastiCache). Mas, além disso, há o Navegador espúrio que nos permite examinar cada um desses serviços usando um navegador da Web padrão. Isso significa que, em vez de perder tempo escrevendo código para filtrar uma longa lista de resultados do S3, posso abrir o Spurious Browser e clicar em alguns links para detalhar o conteúdo no qual estou interessado e, quando o encontrar, posso abrir o conteúdo para visualizá-lo.
O Spurious nasceu da necessidade de criar rapidamente protótipos de novos recursos para nossos Brokers/Renderizadores, mas também para evitar todo o processo de implementação
Ele ainda está em desenvolvimento e tem algumas arestas (há uma reescrita planejada, que mudará a linguagem de implementação de Ruby para Go), mas, no final das contas, temos usado o Spurious em vários projetos e ele se tornou independente. Recomendo enfaticamente que o senhor dê uma olhada.
FP, OOP e MVC
Até agora, neste post, discutimos o sistema de alto nível e o projeto arquitetônico, as ferramentas e outros processos associados. Nesta seção, quero descer um nível e expressar brevemente meu amor pela Programação Funcional (PF), o que exigirá que eu faça algumas comparações com a Programação Orientada a Objetos (OOP).
OOP e FP são dois estilos de desenvolvimento que têm interesses um tanto opostos. A OOP se concentra mais no encapsulamento de dados, enquanto o FP gosta de filtrar dados.
A OOP consiste em classes e na criação de objetos em que os dados ficam ocultos dentro deles, mas o senhor pode manipular os dados por meio de métodos expostos. Já o FP é geralmente uma coleção de funções puras que ajudam a aplicar o transparência referenciale os dados são transmitidos através do essas funções, manipulando-o à medida que avança.
Um dos grandes argumentos de venda da (maioria das) linguagens FP é o suporte à imutabilidade. A imutabilidade é uma forma de distinguir estado, identidade e valor. Do ponto de vista prático: se o senhor modificar os dados, as alterações resultarão em um cópia dos dados originais (em vez de alterá-los).
Temos visto um recente surto de interesse em torno da imutabilidade (e FP em geral) na comunidade JavaScript ultimamente (com Mori.js e immutable-js como alguns exemplos, mas há outros e eles existem há muito mais tempo). A imutabilidade pode ajudar a erradicar toda uma série de bugs que podem pegá-lo de surpresa em uma linguagem tão mutável quanto o JavaScript (e ainda mais em linguagens em que o código pode ser multithread).
Linguagens como Clojure, por exemplo, também implementam estruturas de dados persistentes, que tornam a imutabilidade fácil e econômica. Recomendo visitar o site do site do Clojure e descobrir mais sobre os detalhes da implementação subjacente, pois é uma leitura bastante interessante
Normalmente, o senhor encontrará uma mistura de opiniões: algumas organizações são baseadas em OOP, outras preferem FP. O que vale a pena saber é que essa não é uma situação de “ou ou”. O senhor pode encontrar algumas vantagens em ter os benefícios estruturais/encapsulamento da OOP e, ao mesmo tempo, implementar determinados recursos de forma funcional (mas acho que esse é um assunto para outro dia). A metodologia “OOP com FP” é bastante fácil com uma linguagem como Scala que incorpora perfeitamente os dois estilos em seu design de linguagem.
O senhor também descobrirá que a linguagem de programação Clojure (que não é uma linguagem FP estrita, embora ofereça muitos dos recursos que espera encontrar), na verdade, incorpora determinados princípios de OOP na API da linguagem (pois foi criada sobre a JVM e, portanto, aplica uma sintaxe lisp idiomática para criar classes e interfaces) e em algumas de suas bibliotecas populares desenvolvidas pela comunidade de código aberto. Um exemplo disso é a popular biblioteca Componente biblioteca que permite o gerenciamento mais fácil do ciclo de vida dos componentes de software por meio do encapsulamento de dados.
O motivo da discussão sobre o uso de OOP versus FP é que há diferentes prós e contras em ambos os estilos de desenvolvimento quando se trata de sistemas de software de alto tráfego, distribuídos e simultâneos. Embora sejamos uma organização baseada principalmente em OOP e, por meio de um bom design de código, não tenhamos sofrido nenhum efeito negativo com o uso de OOP, alguns membros da equipe (inclusive eu) foram expostos à maior simplicidade e à redução de bugs que ocorrem inerentemente ao utilizar FP e linguagens que suportam nativamente a imutabilidade.
A imutabilidade é a chave para evitar mutexes e semáforos complexos ao escrever código multithread. Para saber mais sobre o assunto, leia “Thread Safe Concurrency” (Concorrência segura de thread).
Um último ponto que gostaria de abordar é o (ab)uso do MVC padrão.
Em primeiro lugar, não existe um padrão de design oficial chamado “MVC” (ele poderia ser considerado um “padrão arquitetônico”, mas a maioria das pessoas parece se referir a ele como um padrão de design). Trata-se apenas de uma coleção de padrões menores que foram comumente agrupados para formar o que é conhecido como “Model, View, Controller” (para que não sejamos pegos discutindo a confusão sobre por que tantos desenvolvedores projetam seu software em torno de uma única arquitetura MVC global, em vez de várias estruturas MVC menores em seus aplicativos – mas essa é provavelmente uma discussão para outro dia).
Independentemente de sua aparente popularidade, o MVC nem sempre é a ferramenta certa para o trabalho. Vale a pena ficar atento e reconhecer quando se está prestes a cultuar uma determinada tecnologia ou padrão de design, pois, em muitos casos, o MVC pode ser visto como um exagero e acrescentar complexidade e complicações adicionais ao código que não são necessárias. Vamos ser claros aqui: O MVC pode muito bem ser a escolha certa para o senhor, mas eu o aconselharia a investigar os méritos de usá-lo em comparação com um conjunto alternativo de padrões que poderia ajudá-lo a simplificar o design do software (por exemplo, um padrão de observador simples pode ser suficiente para muitos aplicativos; crie camadas de complexidade à medida que forem necessárias, não vá direto para uma estrutura MVC).
O (ab)uso do MVC também se tornou padrão no âmbito das bibliotecas JavaScript de front-end. Novamente, não estou dizendo que o MVC é ruim ou errado, mas o que estou dizendo é “o senhor precisa dele?”. Lembre-se de considerar o que está fazendo quando utiliza uma determinada biblioteca de código aberto (ou mesmo comercial) em seu aplicativo. A simplicidade é a chave.
Complexidade inerente
Existem alguns softwares e ferramentas que são inerentemente complexos por design. Como exemplo, quero demonstrar isso dando uma olhada em nosso pipeline de implantação de aplicativos, que utiliza Jenkins e nos fornece um processo de implantação contínua de círculo completo.
O processo pode ser dividido (grosso modo) nas seguintes etapas:
- Mesclar o código em nosso sistema de controle de versão GitHub
- Um webhook é configurado para o nosso repositório que alerta o Jenkins
- O Jenkins começa a criar nosso primeiro trabalho (extrai códigos e instala dependências)
- Se esse trabalho for aprovado, nosso trabalho será configurado para chamar outro trabalho do Jenkins
- O próximo trabalho executa nossos testes de unidade e, quando eles são aprovados, chama novamente outro trabalho
- O próximo trabalho cria e implementa nosso aplicativo em nosso servidor de integração
- Se a implantação for bem-sucedida, chamaremos outro trabalho que executa nossos testes de integração
- Se os testes falharem, marcaremos o trabalho como falho
- Se os testes forem aprovados, acionamos o próximo trabalho que será implantado em nosso servidor de teste
- Depois de implantada para teste, executamos novamente os testes de integração e marcamos a implantação como bem-sucedida ou com falha
- Se estivermos bem até este ponto, então vamos implantar para viver
Agora, mesmo dividindo esse processo em etapas individuais (simplificadas), tenho certeza de que o senhor pode perceber que esse processo de implementação parecerá bastante complicado na prática; e é mesmo. Temos vários trabalhos que foram abstraídos a um nível em que podemos reutilizá-los em vários projetos diferentes, mas esse processo de abstração torna a compreensão do que está acontecendo bastante complicada porque o senhor precisa alternar o contexto entre o Jenkins e o GitHub.
Um método de abstração que usamos foi tirar proveito da IoC (inversão de controle). Em nossos trabalhos, para nos ajudar a manter um registro das alterações nos scripts de compilação, decidimos que a melhor coisa a fazer era puxar para baixo bash do GitHub e executá-los para implementar uma funcionalidade específica que foi abstraída por trás de uma função reutilizável. É isso que nos permite criar trabalhos genéricos que podem ser reutilizados em muitos projetos diferentes.
Isso aconteceu porque tentamos abordar nossos trabalhos de compilação da mesma forma que faríamos com o código do aplicativo e, embora tenhamos um bom conjunto de trabalhos de compilação DRY, é difícil seguir essa linha (especialmente quando há um erro em uma seção do pipeline de implementação, que pode se tornar bastante difícil de localizar e depurar).
Esse é um dos principais motivos pelos quais achamos que nossa solução atual é “complicada”. Isso ocorre porque o Jenkins não foi projetado com esse tipo de fluxo de trabalho complexo em mente e, portanto, embora existam plug-ins que possam ajudar a visualizar e construir pipelines de implementação completos, eles não são ideais. Não vou entrar em detalhes sobre o motivo, pois isso está um pouco fora do escopo deste artigo, mas acredite em mim: é um pouco complicado fazer com que os pipelines de entrega contínua funcionem de forma realmente tranquila no Jenkins.
Em uma tentativa de simplificar nosso pipeline de implantação, planejamos adotar a seguinte abordagem para resolver nossos problemas com o Jenkins (observe que essa abordagem pode não funcionar para o senhor e, dependendo da sua equipe, sua milhagem pode variar):
- Reduzir nossos vários trabalhos genéricos conectados em um único trabalho, o que significa que passaremos manualmente o ambiente para o qual desejamos que o componente seja implantado toda vez que o trabalho for executado (essa é uma medida temporária, pois nos dá uma linha de base sensata a partir da qual podemos construir)
- Em seguida, investigaremos métodos alternativos para fazer o Jenkins trabalhar com pipelines de implantação complexos (como o Modelos Jenkins)
- Então, quando tivermos capacidade dentro da equipe, procuraremos estabelecer GOCD que configuramos anteriormente como um tech spike e descobrimos que funcionava muito bem com o fluxo de trabalho da nossa equipe.
Contêineres
A partir de 2014/2015, o mundo da tecnologia está se movimentando sobre Docker. Se o senhor quiser saber mais sobre o que é o Docker e como ele funciona, recomendo que visite o site deles, pois há uma grande quantidade de boas informações. Resumindo: um “contêiner” do Docker é um conjunto isolado de processos que pode ser conectado a outros “contêineres” para criar diferentes tipos de aplicativos de software, mas de uma forma mais gerenciável.
Um dos maiores argumentos de venda do Docker é o mantra: “construa uma vez, execute em qualquer lugar”. Isso significa que o senhor pode definir seus requisitos e ter certeza de que eles serão executados da mesma forma, independentemente de sua plataforma ser o AWS ECS, o Google Cloud Compute ou o Tutum.
Um exemplo simples geralmente dado para demonstrar como o Docker pode ser usado em um fluxo de trabalho tradicional de desenvolvimento da Web é: crie um contêiner do Docker que execute seu aplicativo da Web, depois crie outro contêiner que execute seu banco de dados e, em outro contêiner, você pode ter um serviço de cache (por exemplo, Redis ou Memcache). Todos esses contêineres podem ser vinculados pelo Docker para que possam se comunicar com segurança entre si e, ao mesmo tempo, proporcionar isolamento desacoplado.
No entanto, essa descrição não faz justiça ao que o Docker pode oferecer e, se o senhor ainda não brincou com ele, recomendo fortemente que o experimente. Para lhe dar algumas ideias, listei abaixo algumas maneiras diferentes de utilizar o Docker e levantei alguns pequenos pontos sobre o uso dele também.
Aqui estão alguns casos de uso em que aplicamos o Docker:
- Entrega contínua (cada trabalho do Jenkins é um novo contêiner, com um conjunto isolado de dependências – isso nos permite evitar o problema de desenvolvedores que desejam atualizar versões específicas de software e são informados de que não podem fazê-lo porque uma versão atualizada causará problemas em outros produtos)
- Criação dinâmica de sandboxes em tempo de execução que hospedam branches específicos do GitHub (para compartilhamento com as partes interessadas)
- Picos de tecnologia (o Docker permite que nos concentremos nos recursos e não sejamos pegos por problemas de instalação/configuração)
- Ajudando-nos a estruturar e desenvolver melhor o software (Espúrio usa o Docker para executar cada um dos serviços falsos da AWS)
A conteinerização de seus aplicativos provavelmente se tornará o padrão de design de arquitetura de software padrão em um futuro muito próximo, portanto, vale a pena brincar e se familiarizar com as ferramentas disponíveis e com a melhor forma de dividir seu possível monólito em microsserviços desacoplados.
Mas, dito isso, quais são os pontos problemáticos atuais para a conteinerização de todo o seu software? Há momentos em que o senhor não gostaria de usá-lo? Bem, há algumas coisas que vale a pena considerar:
Ferramentas
As ferramentas disponíveis para depurar contêineres ainda são consideradas bastante imaturas. O Docker oferece um log bem como um comando exec (que permite que o senhor entre em um contêiner em execução usando um shell bash); mas pode haver casos em que nenhuma dessas opções será bem-sucedida.
Por exemplo, um contêiner não estava registrando nada e, além disso, o aplicativo (que, quando executado fora do contêiner, seria executado para sempre em um loop infinito) seria executado inicialmente e, em seguida, pararia quando executado dentro do contêiner, e assim o exec não era uma opção, pois eu não podia entrar em um contêiner que não estava mais em execução.
Observação: no binário mais recente, o Docker forneceu estatísticas adicionais que são expostas por meio do
docker stats {container}comando
Dimensionamento
O dimensionamento de contêineres exige uma nova abordagem que pode não se adequar ao seu modelo de infraestrutura atual. Além disso, a questão da escalabilidade poderia ser simplificada pelo próximo lançamento do recurso “Swarm” do Docker, que oferece a capacidade de controlar um cluster de máquinas que executam o Docker por meio de um único endpoint. Porém, a facilidade com que isso se torna realmente escalonamento um cluster de instâncias do docker em execução em um único host, ainda não foi visto na prática.
O escalonamento tradicional “vertical vs. horizontal” é bastante simples: com o escalonamento vertical, o senhor aumenta o tamanho da caixa que executa o aplicativo; já com o escalonamento horizontal, o senhor aumenta o número de caixas. A capacidade de dimensionar horizontalmente um cluster de contêineres do docker pode não ser tão simples.
Imagine que eu tenha uma instância de servidor EC2 em execução com um grupo de escalonamento automático que cria uma nova instância de servidor quando a CPU atinge 70%. Nessa instância, tenho um serviço da Web em execução dentro de um contêiner do Docker e ele está atingindo o máximo de seus recursos. Teríamos que usar métricas personalizadas disparadas do nosso contêiner do Docker para AWS CloudWatchque nos permitiria definir um alarme que acionasse a criação de uma nova instância de servidor. Caso contrário, nosso ASG não detectaria a falha do contêiner do Docker.
Docker Swarm, poderia ajudar aqui (ainda não foi lançado e não tivemos a chance de experimentar um pré-lançamento antecipado)? Mas parece que ele só funciona se o senhor tiver um pool de servidores pré-criado, em vez de instâncias de servidor geradas dinamicamente. Talvez quando tivermos um lançamento oficial e a oportunidade de vê-lo em ação, descobriremos que ele lida perfeitamente com a questão do dimensionamento. Mas até lá, é apenas algo a se considerar antes de ir muito longe com o projeto de sua infraestrutura em torno do Docker.
Orquestração
A execução de contêineres do Docker pode resultar em comandos muito longos que são difíceis de analisar visualmente e levam muito tempo para serem redigitados. Esse é o principal problema das ferramentas de orquestração, como a (que será lançada em breve) Docker Compose estão tentando resolver. Usei uma versão inicial do Docker Compose e ela parece promissora. Definitivamente, ele ajuda a documentar a configuração da infraestrutura (assim como o AWS CloudFormation faz) e permite ambientes facilmente reproduzíveis.
Camadas
Na verdade, essa é uma preocupação bastante específica e que pode não ter nenhuma base prática ou solução realista (do ponto de vista da implementação ou porque já existem soluções alternativas), mas descobri que criar imagens que precisam utilizar credenciais de autenticação de segurança privada é mais complicado do que parece.
Ao criar uma imagem do Docker, o senhor a constrói a partir de várias camadas (isso permite que o Docker crie uma imagem usando camadas em cache e melhorando muito o desempenho da criação), mas isso significa que, se o senhor adicionar suas credenciais de segurança, elas serão incorporadas à imagem resultante. Eu preferiria que fosse possível remover camadas para que o senhor pudesse adicionar as credenciais, extrair mais recursos dentro da imagem do Docker e, em seguida, remover a camada que incluía suas credenciais.
A solução para isso é criar uma nova imagem a partir de um contêiner já em execução que já tenha montado suas credenciais. Não há nada necessariamente errado com essa abordagem, mas ela também não parece muito limpa. Posso estar reclamando por nada, mas isso é algo que me marcou. Gostaria de saber como outras organizações e desenvolvedores estão lidando com a criação de imagens com autenticação privada.
Uma sugestão alternativa do Steven Jack foi que talvez o Docker pudesse adicionar variáveis de ambiente no momento da construção. Isso permitiria que o senhor fornecesse suas credenciais de segurança no momento da construção da imagem, em vez de tê-las embutidas na imagem. Por exemplo:
docker build -t some/image -e MY_SECRET=KEY
Otimização da experiência do usuário
Eu disse no início deste post que não abordaria muitas tecnologias de front-end porque elas são vastas, complexas e os padrões recomendados parecem mudar regularmente. Mas isso não quer dizer que não existam coisas que o senhor deva fazer ao projetar seus aplicativos voltados para o usuário. Abaixo, há uma pequena lista de tópicos que o senhor deveria investigar:
- Desempenho: desde 2007 Steve Souders tem sido o padrinho do desempenho de front-end. Leia seus livros e suas publicações no blog. O senhor verá uma grande melhoria ao seguir suas práticas recomendadas (que são praticamente o padrão do setor hoje em dia).
- Reagir é uma “biblioteca JavaScript para a criação de interfaces de usuário”. Não vou entrar em detalhes sobre a biblioteca aqui, mas basta dizer que ela oferece muitos recursos interessantes, como a implementação de um DOM virtual para alto desempenho, a ausência de modelos para a criação de interfaces e o fato de evitar a vinculação de dados bidirecional em favor da “reconciliação de diferenças”.
- Imutabilidade: esse é um princípio da programação funcional e finalmente está começando a crescer na comunidade JavaScript. Há algumas bibliotecas diferentes disponíveis para dar suporte a dados imutáveis, como immutable-js e Mori. Eu recomendaria que o senhor experimentasse essas bibliotecas, pois a imutabilidade pode ajudar a reduzir uma série de bugs difíceis de serem resolvidos.
- BEM: Block Element Modifier é uma notação predescrita para escrever CSS que permite reduzir a complexidade/especificidade e, ao mesmo tempo, aumentar a capacidade de manutenção e reutilização. Harry Roberts escreveu extensivamente sobre isso e, na verdade, eu recomendaria a leitura de tudo o que ele tem a dizer sobre CSS e como escrevê-lo para dar suporte a aplicativos de grande escala.
- RWD: o design responsivo da Web não é um tópico novo nem fácil. Há uma infinidade de técnicas para implementar o RWD adequadamente e de forma progressivamente aprimorada/com desempenho. Eu recomendaria a leitura de tudo o que o Brad Frost tem a dizer. Veja a opinião dele Biblioteca de padrões para obter muitos bons exemplos de código.
Onde tivemos sucesso/fracasso?
Admitir o fracasso nunca é fácil e, por isso, não é comum ver posts em blogs descrevendo como algum novo recurso ou tecnologia não funcionou como planejado. Pessoalmente, sou da opinião de que reconhecer as situações em que falhamos (e tentar “falhar rapidamente”) é uma maneira saudável de reagir. Assim como no mundo da computação distribuída, é preciso aceitar o fato de que os serviços vão falhar e, em vez disso, concentrar-se em melhorar a situação, caso ela ocorra.
Com isso em mente, posso dizer que nosso pipeline de implantação atual (usando o Jenkins) não funcionou muito bem para nós (conforme descrito anteriormente neste post). Ele é um pouco complicado e definitivamente parece complicado demais para ser usado por muito tempo. Fazer alterações em nosso processo de implementação não é fácil e pode levar algum tempo para que um engenheiro crie um modelo mental do pipeline em sua cabeça. Não deveríamos ter que seguir um thread da maneira que estamos fazendo no momento.
Além disso, embora marquemos uma versão como falha se algum dos testes de unidade/integração falhar, ainda temos que reverter manualmente a versão, o que não é nada bom. É difícil explicar por que isso ainda não foi resolvido, sem nos perdermos em detalhes técnicos que são muito específicos da nossa infraestrutura. Esse é um problema que ainda estamos muito interessados em resolver para que possamos ter uma verdadeira experiência de CD.
Dito isso, estamos cientes desse problema e estamos procurando resolvê-lo de forma proativa, seguindo estas etapas:
- Simplifique o problema (obtenha uma linha de base que funcione)
- Realizar uma pesquisa técnica para o GOCD (entender se ele atenderá às nossas necessidades)
- Implemente uma nova solução com base nos resultados de um pico técnico (ou seja, GOCD ou modelo Jenkins)
A Entrega Contínua pode ser um problema difícil de resolver de forma descomplicada. Portanto, o senhor precisa ser prático na abordagem para encontrar uma solução.
Outra coisa que percebi é que estamos lentamente fazendo um culto de carga ao nosso estrutura Alephant. Com isso quero dizer: estamos encontrando cada vez mais maneiras de adaptar a estrutura ao projeto em vez de projetar uma solução em torno do espaço do problema. Isso não deveria acontecer. Cada projeto tem um conjunto exclusivo de requisitos que precisam ser considerados; e se o problema puder ser resolvido de forma agradável e eficiente usando o padrão “broker/renderer” pré-descrito que o Alephant Framework implementa, então ótimo. Mas não devemos nos sentir obrigados a usá-lo… o senhor sabe, só porque sim.
Com relação às nossas bibliotecas RPM abstraídas: embora tenhamos separado determinadas funcionalidades relacionadas em bibliotecas individuais, ainda podemos extrair determinadas configurações em suas próprias bibliotecas isoladas. Por exemplo, nossa “Base de componentes” inclui a configuração do registro em uma instância do servidor, bem como a definição da configuração específica do aplicativo. Alguns de nossos componentes literalmente só precisam que o registro seja fornecido “fora da caixa” e nada mais; portanto, extrair isso para uma biblioteca de registro significa que esses componentes podem exigi-lo como uma dependência e, ao mesmo tempo, permitir que a “Base de componentes” também o consuma. Isso nos dá ainda mais flexibilidade e granularidade de controle.
Quando originalmente estávamos criando nossa solução de monitoramento, conseguimos criar um protótipo muito rápido usando o Docker. Tínhamos contêineres ligados entre si que usavam Graphite e Grafana, mas logo percebemos que essa configuração não seria dimensionada quando o Chaos Monkey apareceu e destruiu nossa instância de uma só vez. Precisávamos que esses serviços fossem desacoplados para melhorar a resiliência. Esse foi um caso em que o Docker não era necessariamente a melhor ferramenta para o trabalho. Isso nos ajudou a melhorar nossa solução, passando a usar o InfluxDB e, assim, reduziu as partes móveis (já que o Graphite é, na verdade, composto por três aplicativos separados: Whisper, Carbon e Graphite-web). Pudemos então executar o InfluxDB e o Grafana como serviços separados usando aplicativos tradicionais em vez do Docker.
Em alguns casos, tivemos sucesso ao nos pegarmos tentando projetar soluções específicas em excesso. Por exemplo, recentemente tivemos a necessidade de arquivar alguns componentes que a Alephant Framework usava para renderizar. Precisávamos mover os componentes renderizados de um bucket S3 para outro bucket S3. Esse processo de arquivamento só aconteceria uma vez (após o evento ao qual os componentes estavam associados, portanto, não era um serviço que precisava ser executado 24 horas por dia, 7 dias por semana). Inicialmente, começamos a configurar um servidor EC2 e tudo o que acompanha a implementação por meio de nossa própria infraestrutura (que é uma abstração sobre o AWS), mas descobrimos que a melhor solução era utilizar o novo (a partir de 2015) AWS Lambda que foi criado especificamente para esses cenários baseados em eventos isolados. Isso ajudou a simplificar a solução em si, além de reduzir os custos gerais. Além disso, tivemos a oportunidade de brincar com algumas novas tecnologias, o que é sempre divertido 🙂
Resumo
Então, aqui estamos finalmente no final de minha viagem pelo design de software e ferramentas. Cobrimos principalmente as tecnologias relacionadas ao back-end/dev-ops e, de forma breve, consideramos algumas dicas para o front-end.
É difícil reduzir muitos anos de experiência em front-end e back-end em uma única publicação de blog. Em vez disso, o senhor poderia escrever um livro (ou dois, ou três). A ideia por trás desta postagem foi fornecer uma amostra do processo de pensamento atual com relação a toda a nossa pilha de tecnologia a partir de 2015. Algumas dessas ideias se tornarão prática padrão, outras desaparecerão silenciosamente. Mas devemos estar sempre abertos a mudanças e experimentações e a encontrar maneiras de simplificar nossos processos, em vez de superprojetá-los e promover uma complexidade desnecessária.
Espero que parte do que o senhor leu aqui tenha sido esclarecedor. Sinta-se à vontade para entrar em contato comigo pelo GitHub ou pelo Twitter usando o nome “integralist”.



Sobre Mark McDonnell
Líder técnico/Engenheiro principal da @BBCNews. Escreve principalmente código com Clojure e JRuby (com interesse em Go). Trabalha com sistemas distribuídos e de grampo; sistemas simultâneos. Autor de Pro Vim publicado pela Apress.