
A programação reativa tomou o JavaScript de assalto na última década, e por um bom motivo: o desenvolvimento front-end se beneficia muito da simplicidade de escrever código de interface do usuário que “reage” às alterações de dados, eliminando o código imperativo propenso a erros substanciais encarregado de atualizar as interfaces do usuário. Entretanto, embora a popularidade tenha aumentado, as ferramentas e as técnicas nem sempre acompanharam a funcionalidade dos navegadores modernos, as APIs da Web, os recursos de linguagem e os algoritmos ideais para desempenho, escalabilidade, facilidade sintática e estabilidade de longo prazo. Nesta postagem, vamos analisar algumas das tecnologias, técnicas e recursos mais recentes que estão disponíveis agora e demonstrá-los no contexto de uma nova biblioteca, Alkali.
As técnicas que analisaremos incluem renderização em fila, reatividade granular baseada em pull, geradores e expressões ES6 reativos, componentes reativos nativos da Web e fluxo direcional reversível. Essas abordagens são mais do que apenas uma programação orientada por modismos, elas são o resultado de tecnologias de navegador adotadas e de pesquisa e desenvolvimento incrementais que produzem melhor desempenho, código mais limpo, interoperabilidade com componentes futuros e encapsulamento aprimorado. 
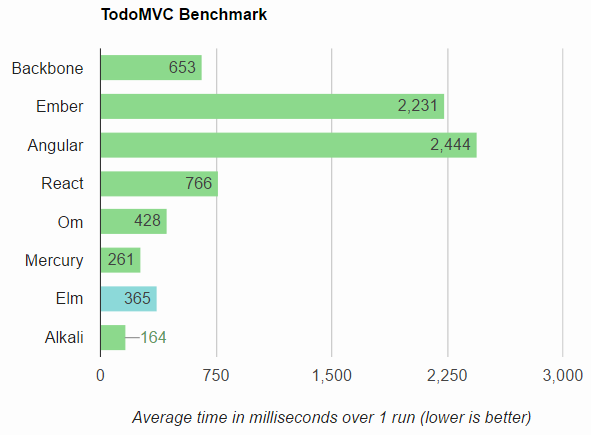
Mais uma vez, analisaremos o Alkali para obter exemplos do resultado de um estilo declarativo simples e sucinto (o senhor pode pular para ver o Aplicativo todo-mvc do Alkali para obter um exemplo mais completo) com arquitetura de elemento nativo padrão e talvez o recurso mais importante que podemos criar: desempenho rápido com consumo mínimo de recursos. Essas técnicas modernas realmente geram benefícios substanciais de desempenho, eficiência e escalabilidade. E, com a constante agitação de novas bibliotecas, a arquitetura mais presciente e estável é a construção direta na API de elementos/componentes do navegador baseada em padrões.
Reatividade Push-Pull
Uma chave para dimensionar a programação reativa é o fluxo arquitetônico de dados. Uma abordagem ingênua da reatividade é usar um padrão simples de observável ou ouvinte para enviar cada atualização por meio de um fluxo com cada avaliação para cada ouvinte. Isso pode resultar rapidamente em cálculos excessivos em qualquer tipo de atualização de estado em várias etapas, o que leva a avaliações intermediárias repetidas desnecessariamente. Uma abordagem mais dimensionável é usar a abordagem baseada em “pull”, em que todos os dados computados são calculados de forma preguiçosa quando o observador downstream solicita ou “puxa” o valor mais recente. Os observadores podem solicitar dados usando de-bouncing ou enfileiramento após serem notificados de que os dados dependentes foram alterados.
Uma abordagem baseada em pull também pode ser usada em conjunto com o armazenamento em cache. À medida que os dados são computados, os resultados podem ser armazenados em cache, e as notificações de alterações upstream podem ser usadas para invalidar caches downstream para garantir o frescor. Esse esquema de cache e invalidação da reatividade baseada em pull segue a mesma arquitetura de design do REST, o design dimensionável da Web, bem como a arquitetura dos processos de renderização dos navegadores modernos.
Há, no entanto, situações em que é preferível que determinados eventos sejam “empurrados”, onde eles atualizam o estado atual de forma incremental. Isso é particularmente útil para atualizações progressivas de coleções em que os itens podem ser adicionados, removidos ou atualizados sem propagar todo o estado da coleção. A abordagem de desempenho mais abrangente é híbrida: o fluxo de dados é extraído principalmente do observador, mas as atualizações incrementais podem ser enviadas por meio de fluxos de dados em tempo real como uma otimização.
Renderização em fila
A chave para aproveitar as dependências reativas baseadas em pull para obter eficiência em aplicativos reativos é garantir que a execução da renderização seja minimizada. Frequentemente, várias partes de um aplicativo podem atualizar o estado do aplicativo, o que pode facilmente levar a falhas e ineficiência se a renderização for executada de forma síncrona imediatamente em qualquer alteração de estado. Ao enfileirar a renderização, podemos garantir que, mesmo quando ocorrerem várias alterações de estado, a renderização seja minimizada.
O enfileiramento de ações ou o “de-bouncing” é uma técnica relativamente comum e bem conhecida. No entanto, para otimizar o enfileiramento da renderização, os navegadores, na verdade, oferecem uma excelente alternativa às funções genéricas de eliminação de saltos. Devido ao seu nome, requestAnimationFrame costuma ser relegada às bibliotecas de animação, mas essa API moderna é, na verdade, perfeita para enfileirar a renderização de alterações de estado. requestAnimationFrame é uma tarefa de macroevento, portanto, todas as microtarefas, como resoluções de promessas, poderão ser concluídas primeiro. Ela também permite que os navegadores determinem com precisão o melhor momento para renderizar novas alterações, levando em consideração a última renderização, a visibilidade da guia/navegador, a carga atual etc. A chamada de retorno pode ser executada sem atraso (geralmente abaixo de um milésimo de segundo) no estado visível em repouso, em uma taxa de quadros apropriada em situações de renderização sequencial e até mesmo completamente adiada quando uma página/aba está oculta. Na verdade, ao enfileirar as alterações de estado com requestAnimationFramee renderizando-as conforme necessário para a atualização visual, estamos na verdade seguindo o mesmo fluxo de renderização otimizado, o tempo preciso e a sequência/caminho que os próprios navegadores modernos usam. Essa abordagem garante que estamos trabalhando de forma complementar com os navegadores para renderizar de forma eficiente e oportuna, sem incorrer em layouts extras ou repinturas.
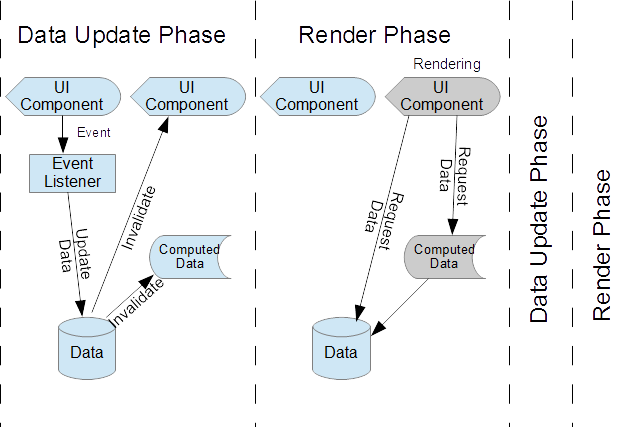
Isso pode ser considerado como uma abordagem de renderização de duas frases. A primeira fase é uma resposta aos manipuladores de eventos em que atualizamos as fontes de dados canônicas, o que aciona a invalidação de dados derivados ou de componentes que dependem desses dados. Todos os componentes de UI invalidados são colocados na fila para renderização. A segunda fase é a fase de renderização, na qual os componentes recuperam os dados necessários e os renderizam.
A Alkali aproveita esse enfileiramento renderizado por meio de seu objetos renderizadoresque conectam entradas de dados reativas (chamadas de “variáveis” no alkali) a um elemento e, em seguida, colocam em fila todas as alterações de estado para serem renderizadas novamente por meio do requestAnimationFrame . Isso significa que todas as ligações de dados são conectadas a renderizações em fila. Isso pode ser demonstrado pela criação de um valor reativo com o Variable e conectando-o a um elemento (aqui criamos um <div>). Vamos dar uma olhada em um código de exemplo:
import { Variable, Div } from 'alkali'
// create a variable
var greeting = new Variable('Hello')
// create div with the contents connected to the variable
body.appendChild(new Div(greeting)) // note that this is a standard div element
// now updates to the variable will be reflected in the div
greeting.put('Hi')
// this rendering mechanism will be queue the update to the div
greeting.put('Hi again')
Essa conexão atualizará automaticamente o div usando o requestAnimationFrame sempre que o estado mudar, e várias atualizações não causarão várias renderizações, apenas o último estado será renderizado.
Reatividade granular
A programação de reatividade funcional pura permite que sinais ou variáveis individuais sejam usados e propagados por um sistema. Entretanto, com o objetivo de manter a familiaridade da programação imperativa, as estruturas reativas baseadas em diferenças, como o ReactJS, que usam um DOM virtual, tornaram-se muito populares. Elas permitem que os aplicativos sejam escritos da mesma forma que poderíamos escrever um aplicativo com código imperativo. Quando o estado do aplicativo muda, os componentes simplesmente são renderizados novamente e, uma vez concluídos, a saída do componente é comparada com a saída anterior para determinar as alterações. Em vez de fluxos de dados explícitos que geram alterações específicas na interface do usuário renderizada, a comparação compara a saída da reexecução com os estados anteriores.
Embora isso possa produzir um paradigma muito familiar e conveniente para a codificação, ele tem um custo significativo em termos de memória e desempenho. A reatividade de difusão requer uma cópia completa da saída renderizada e algoritmos de difusão complexos para determinar as diferenças e atenuar a reescrita excessiva do DOM. Esse DOM virtual normalmente requer de 2 a 3 vezes o uso de memória de um DOM sozinho, e os algoritmos de difusão adicionam uma sobrecarga semelhante em comparação com as alterações diretas do DOM.
Por outro lado, a verdadeira programação reativa funcional define explicitamente as “variáveis” ou os valores que podem mudar e a saída contínua desses valores à medida que eles mudam. Isso não exige nenhuma sobrecarga adicional ou algoritmos de diferenciação, pois a saída é especificada diretamente pelas relações definidas no código.
A depuração também se beneficia do fluxo de código reativo funcional granular. A depuração da programação imperativa envolve recriar condições e percorrer blocos de código, exigindo raciocínio complexo para avaliar como o estado muda (e como está dando errado). Os fluxos reativos funcionais podem ser inspecionados estaticamente, onde sempre temos visibilidade total do gráfico de entradas dependentes individuais que correspondem à saída da interface do usuário, em qualquer ponto no tempo.
Mais uma vez, o uso de técnicas de programação funcionalmente reativas não é apenas um esforço esotérico ou pedante da ciência da computação, mas uma abordagem com benefícios significativos para a escalabilidade, a velocidade, a capacidade de resposta, a facilidade de depuração e o fluxo do seu aplicativo.
Dados canônicos e reversíveis
O fluxo explícito de reatividade granular também possibilita reverter os fluxos de dados para obter ligações bidirecionais, de modo que os consumidores de dados downstream, como elementos de entrada, possam solicitar alterações de dados upstream sem configuração extra, fiação ou lógica imperativa. Isso torna extremamente fácil criar e vincular os controles de entrada em formulários.
Um princípio importante da reatividade é a “fonte única de verdade”, em que há uma distinção explícita entre fontes de dados canônicos e dados derivados. Os dados reativos podem ser descritos como um gráfico direcionado de dados. Isso é vital para o gerenciamento coerente de dados. A sincronização de vários estados de dados sem uma direção clara da fonte e dos dados derivados torna o gerenciamento de dados confuso e leva a vários problemas de gerenciamento de declarações.
O fluxo unidirecional com alterações centralizadas de dados, associado à reatividade difusa, é uma forma de um gráfico direcionado de dados adequado. Infelizmente, o fluxo unidirecional significa, em última análise, que os consumidores de dados devem ser conectados manualmente aos dados de origem, o que normalmente viola o princípio da localidade e degrada gradualmente o encapsulamento, resultando em um tratamento de estado cada vez mais emaranhado entre componentes independentes e separáveis e em um desenvolvimento de formulários mais complicado.
No entanto, um gráfico direcionado com fonte canônica não dita necessariamente que os dados só podem ser comunicados em uma direção por meio do gráfico. Com a reatividade granular, podemos oferecer suporte ao fluxo reversível. Com a reversibilidade, a direcionalidade ainda pode ser preservada pela definição de alterações de dados downstream como uma notificação de uma alteração que já ocorreu ou foi iniciada (no passado), enquanto, em contrapartida, uma alteração de dados upstream é definida como uma solicitação para que uma alteração seja iniciada (no futuro e revogável). Uma solicitação de alteração de dados derivados ainda pode ser feita, desde que haja uma transformação reversa para propagar a solicitação para uma fonte (as travessias ou transformações reversíveis de dados são geralmente chamadas de “lente” na terminologia funcional). A alteração canônica de dados ainda acontece na fonte de dados, mesmo que seja iniciada/solicitada por um consumidor downstream. Com essa distinção clara de fluxo, o gráfico direcionado de fontes canônicas e dados derivados ainda é preservado, mantendo a consistência no estado e, ao mesmo tempo, permitindo o encapsulamento na interação com entidades de dados individuais, independentemente de serem ou não derivadas. Em termos práticos, isso simplifica o desenvolvimento da entrada do usuário e o gerenciamento de formulários, além de incentivar o encapsulamento dos componentes de entrada.
Extensões DOM modernas (“Componentes da Web”)
A previsão é essencial para o desenvolvimento e a manutenção de longo prazo, e isso é um desafio no ecossistema JavaScript, em que várias tecnologias estão surgindo constantemente. Que nova estrutura será interessante daqui a três anos? Se o passado for um indicador, isso é muito difícil de prever. Como desenvolvemos com esse tipo de rotatividade? A abordagem mais confiável é minimizar nossa dependência de APIs específicas de biblioteca e maximizar nossa dependência de APIs e arquitetura de navegador padrão. E com as APIs e a funcionalidade dos componentes emergentes (também conhecidos como “componentes da Web”), isso está se tornando muito mais viável.
Estruturas reativas bem definidas não devem ditar uma arquitetura de componentes específica, e a flexibilidade de usar componentes nativos ou de terceiros maximiza as possibilidades de desenvolvimento futuro. Entretanto, embora possamos e devamos minimizar o acoplamento, algum nível de integração pode ser útil. Em particular, poder usar diretamente as variáveis como entradas ou propriedades é certamente mais conveniente do que ter de criar associações após o fato. Além disso, a integração com o ciclo de vida do elemento/componente e a notificação de quando os elementos são removidos ou desvinculados podem facilitar a limpeza automática de dependências e mecanismos de escuta para evitar vazamentos de memória, minimizar o consumo de recursos e simplificar o uso do componente.
Novamente, os navegadores modernos tornaram esse tipo de integração com elementos nativos totalmente viável. Agora é possível estender os protótipos HTML existentes para classes personalizadas reais baseadas em DOM, com construtores reativos com reconhecimento de variáveis e o MutationObserver (e possíveis retornos de chamada de componentes da Web no futuro) nos dão a capacidade de monitorar quando os elementos são desanexados (e anexados). A funcionalidade getter/setter introduzida no ES5 também nos permite estender e reproduzir adequadamente as propriedades de estilo de elementos nativos.
O Alkali define um conjunto de construtores/classes DOM com exatamente essa funcionalidade. Essas classes são extensões mínimas das classes DOM nativas com construtores com argumentos que suportam entradas de variáveis que acionam propriedades e limpeza automatizada de variáveis. Em conjunto com a reatividade baseada em lazy/pull, isso significa que os elementos exibem dados de forma reativa enquanto estão visíveis e, uma vez desvinculados, não acionam mais nenhuma avaliação por meio de sua dependência de entradas. Isso resulta em uma criação e extensão de elementos com autolimpeza automatizada de ouvintes. Por exemplo:
let greetingDiv = new Div(greeting) body.appendChild(greetingDiv) // a binding will be created that listens for changes to greeting ... body.removeChild(greetingDiv) // binding/listener of greeting will be cleaned up
Geradores reativos
Além de as APIs da Web proporcionarem melhorias importantes em nossa abordagem à reatividade, a própria linguagem ECMAScript tem novos recursos interessantes que podem ser usados para melhorar a sintaxe e a facilidade de escrever código reativo. Um dos novos recursos mais avançados são os geradores, que oferecem uma sintaxe elegante e intuitiva para o fluxo de código interativo. Talvez o maior inconveniente de trabalhar com dados reativos em JavaScript seja a necessidade frequente de funções de retorno de chamada para lidar com alterações de estado. No entanto, as novas funções de gerador do ECMAScript permitem pausar, retomar e reiniciar uma função de modo que ela possa utilizar entradas de dados reativos com sintaxe sequencial padrão, pausando e retomando para quaisquer entradas assíncronas. Os controladores do gerador também podem se inscrever automaticamente em entradas dependentes e reexecutar a função quando as entradas forem alteradas. Esse controle da execução da função possibilitado pelos geradores pode ser aproveitado para produzir (trocadilho intencional!) uma sintaxe intuitiva e fácil de seguir para combinações complexas de entradas variáveis.
Os geradores foram antecipados pela forma como eliminam retornos de chamada com promessas e permitem uma sintaxe sequencial intuitiva. Mas os geradores podem ser levados ainda mais longe, não apenas para pausar e retomar a entrada assíncrona, mas também para reiniciar quando qualquer valor de entrada for alterado. Isso pode ser feito com o uso da função yield na frente de qualquer entrada de variável, o que permite que o código de coordenação ouça as alterações na variável e retorne o valor atual da variável para o yield expressão quando ele estiver disponível.
Vamos dar uma olhada em como isso é feito. No Alkali, as funções geradoras podem ser usadas como uma transformação para variáveis de entrada, para criar uma função reativa que gera uma nova variável composta com o react. O react atua como um controlador de gerador para lidar com variáveis reativas. Vamos analisar um exemplo disso:
let a = new Variable(2)
let aTimesTwo = react(function*() {
return 2 * yield a
})
O react lida com a execução do gerador fornecido. Uma função de gerador retorna um iterador que é usado para interagir com o gerador, e o react inicia o iterador. O gerador será executado até avaliar um yield operador. Aqui, o código encontrará imediatamente o operador yield e retornará o controle para o operador react com o valor fornecido ao operador yield retornado do iterador. Nesse caso, o operador a será retornada para o react . Isso dá ao react a oportunidade de fazer várias coisas.
Primeiro, ele pode se inscrever ou ouvir a variável reativa fornecida (se for uma), para que possa reagir a quaisquer alterações reexecutando. Em segundo lugar, ele pode obter o estado ou o valor atual da variável reativa, de modo que possa retorná-lo como o resultado de yield quando retomar a execução. Finalmente, antes de retornar o controle, react pode verificar se a variável reativa é assíncrona, mantendo uma promessa de valor e aguardando a resolução da promessa antes de retomar a execução, se necessário. Quando o estado atual for recuperado, a função geradora poderá ser retomada com o valor de 2 retornado da yield a . Se mais yield expressões forem encontradas, elas serão resolvidas sequencialmente da mesma forma. Nesse caso, o gerador retornará um valor de 4, o que encerrará a sequência do gerador (até que o a mude e ela seja reexecutada).
Com o alcalino react essa execução é encapsulada em outra variável reativa composta, e qualquer alteração na variável não acionará a reexecução até que os dados downstream a acessem ou solicitem.
As funções geradoras do Alkali também podem ser usadas diretamente nos construtores de elementos para definir uma função de renderização que será reexecutada automaticamente sempre que um valor de entrada for alterado. Em ambos os casos, usamos a função yield na frente de qualquer variável. Por exemplo:
import { Div, Variable } from 'alkali'
let a = new Variable(2)
let b = new Variable(4)
new Div({
*render() {
this.textContent = Math.max(yield a, yield b)
}
})
Isso cria um <div> com um conteúdo de texto de 4 (o máximo dos dois valores de entrada). Podemos atualizar qualquer uma das variáveis, e ele será reexecutado:
a.put(5)
O <div> seria agora atualizado para ter um conteúdo de 5.
Os geradores não estão universalmente disponíveis em todos os navegadores (não no IE e no Safari), mas os geradores podem ser transpilados e emulados (com o Babel ou outras ferramentas).
Propriedades e Proxies
A vinculação reativa às propriedades do objeto é um aspecto importante da reatividade. Mas para encapsular uma propriedade com notificação de alterações, é necessário mais do que apenas o valor atual da propriedade retornado pelo acesso padrão à propriedade. Consequentemente, os vínculos ou as variáveis de propriedades reativas podem exigir uma sintaxe detalhada.
No entanto, outro novo recurso interessante do ECMAScript são os proxies, que nos permitem definir um objeto que pode interceptar todos os acessos e modificações de propriedades com funcionalidade personalizada. Essa é uma funcionalidade poderosa, que pode ser usada para retornar variáveis de propriedade reativas por meio do acesso normal à propriedade, permitindo uma sintaxe conveniente e idiomática com objetos reativos.
Infelizmente, os proxies não são emulados tão facilmente por meio de compiladores de código como o Babel. A emulação de proxies exigiria não apenas a transpilação do próprio construtor do proxy, mas também de qualquer código que pudesse acessar o proxy, de modo que a emulação sem suporte à linguagem nativa seria incompleta ou excessivamente lenta e inchada devido à transpilação maciça necessária de cada acesso à propriedade em um aplicativo. Mas é possível fazer uma transpilação mais direcionada do código reativo. Vamos dar uma olhada nisso.
Expressões reativas
Embora o EcmaScript esteja em constante evolução, ferramentas como o Babel e seu recurso de plug-in nos dão grandes oportunidades de criar novos recursos de linguagem compilada. E, embora os geradores sejam fantásticos para criar uma função com uma série de etapas que podem ser executadas de forma assíncrona e reexecutadas de forma reativa, com um plug-in Babel, o código pode ser transformado para realmente criar fluxos de dados totalmente reativos, com associações de propriedades, usando a sintaxe do ECMAScript. Isso vai além da simples reexecução, mas a saída das expressões pode ser definida em relação às entradas, de modo que operadores reversíveis, propriedades reativas e atribuições reativas possam ser gerados usando expressões simples e idiomáticas.
Um projeto separado abriga um plug-in babel baseado em álcali para transformar expressões reativas. Com ele, podemos escrever uma expressão normal como um argumento para um react call/operator:
let aTimes2 = react(a * 2)
Este aTimes2 será vinculado à multiplicação da variável de entrada. Se alterarmos o valor de a (usando a.put()), aTimes2 será atualizado automaticamente. Mas como se trata de uma vinculação bidirecional por meio de um operador bem definido, os dados também são reversíveis. Podemos atribuir um novo valor ao aTimes2 do 10, então a será atualizado para um valor de 5.
Conforme mencionado, é quase impossível emular proxies em toda uma base de código, mas em nossas expressões reativas, é muito razoável compilar a sintaxe de propriedade para lidar com propriedades como variáveis reativas. Além disso, outros operadores podem ser transpilados para transformações reversíveis de variáveis. Por exemplo, poderíamos escrever combinações complexas com código de nível de linguagem totalmente reativo:
let obj, foo
react(
obj = {foo: 10}, // we can create new reactive objects
foo = obj.foo, // get a reactive property
aTimes2 = foo // assign it to aTimes2 (binding to the expression above)
obj.foo = 20 // update the object (will reactively propagate through foo, aTimes2, and to a)
)
a.valueOf() // -> 10
Modernização
O desenvolvimento da Web é um mundo empolgante de constante mudança e progresso. E a reatividade é um conceito de programação poderoso para a arquitetura sólida de aplicativos avançados. A reatividade pode e deve crescer para usar as novas tecnologias e os recursos mais recentes do navegador moderno e de sua linguagem e APIs. Juntos, eles podem dar mais um passo à frente no desenvolvimento da Web. Estou entusiasmado com as possibilidades e espero que essas ideias possam avançar nas maneiras como podemos aproveitar o futuro com novas ferramentas.
O Alkali foi desenvolvido por nossa equipe de engenharia, em Evidência médicaA Doctor Evidence, Inc., tem trabalhado para criar ferramentas interativas e responsivas para explorar, consultar e analisar grandes conjuntos de dados de estudos médicos clínicos. Tem sido um desafio fascinante manter uma interface de usuário suave e interativa com dados complexos e vastos, e muitas dessas abordagens têm sido muito úteis para nós, à medida que adotamos novas tecnologias de navegador no desenvolvimento de nosso software da Web. Se nada mais acontecer, esperamos que o Alkali possa servir de exemplo para inspirar mais avanços no desenvolvimento da Web.



Sobre Kris Zyp
Kris Zyp está envolvido na comunidade JavaScript da Web há muitos anos, ajudando a definir especificações, incluindo JSON Schema, Promises/A e AMD, e a criar e contribuir para projetos de código aberto, incluindo Dojo, Persevere e outros. Kris mora com sua esposa e dois filhos em Utah, onde adoram esquiar, caminhar, andar de bicicleta e escalar. Ele trabalha para a Doctor Evidence, desenvolvendo software da Web para agregação e análise estatística de estudos médicos clínicos.