
A pergunta sobre por que precisamos empregar a engenharia reversa é fácil de responder. Quando há um executável, mas não há acesso ao código-fonte, e ainda assim o senhor precisa entender o funcionamento interno desse software específico, aplica-se a engenharia reversa a ele. As situações de negócios em que a engenharia reversa será útil são muitas e muito variadas:
- Pesquisando problemas complexos de software
- Melhoria da compatibilidade com soluções e formatos fechados
- Melhorar a interação com uma plataforma específica
- Facilitando a manutenção do código legado
Há muitos outros casos em que o senhor precisa fazer engenharia reversa de software. Neste artigo, veremos o seguinte como fazer a engenharia reversa de um aplicativo iOSe também do software OS X, e tentarei dar algumas orientações práticas sobre o que o senhor precisa saber e quais ferramentas precisa ter.
Entendendo a estrutura binária
Ao fazer a engenharia reversa de um binário, o senhor deve saber onde o código executável está situado dentro dele. Conhecer a estrutura binária é fundamental para aprender com sucesso a fazer engenharia reversa de software.
Formato binário executável. O formato Mach-O de executável é muito comumente usado entre os sistemas baseados no kernel Mach. Ele pode estar contido em binários “finos” ou binários “gordos”. Enquanto o binário fino tem um único executável Mach-O, o binário gordo pode ter muitos deles ao mesmo tempo. Os fat binaries são normalmente empregados para combinar código executável em um único arquivo.
Cabeçalho. A parte mais importante do executável do iOS ou OS X é o cabeçalho. O cabeçalho é a primeira coisa que o carregador lê ao carregar a imagem. Portanto, o cabeçalho é algo com que todo binário começa. O cabeçalho sempre começa com um número mágico que serve para fins de identificação. Diferentes tipos de binários empregam diferentes cabeçalhos, sendo que os binários thin usam o cabeçalho mach e os binários fat usam seu próprio cabeçalho fat, usado para descrever onde estão localizados todos os cabeçalhos mach do binário.
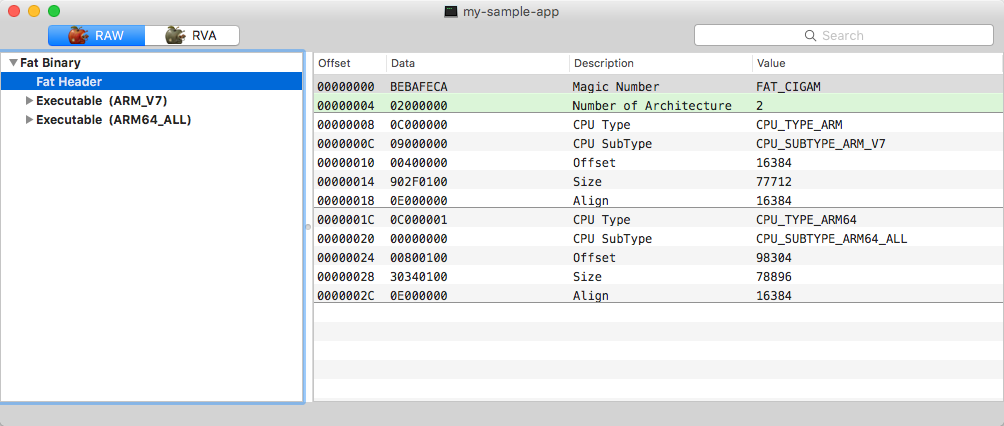
O cabeçalho fat começa com o número mágico 0xcafebabe e contém informações sobre cada executável que reside no arquivo binário: Tipo e subtipo de CPU, deslocamento do arquivo e valores de alinhamento.
cyber
 Fat Header do executável “fat
Fat Header do executável “fat
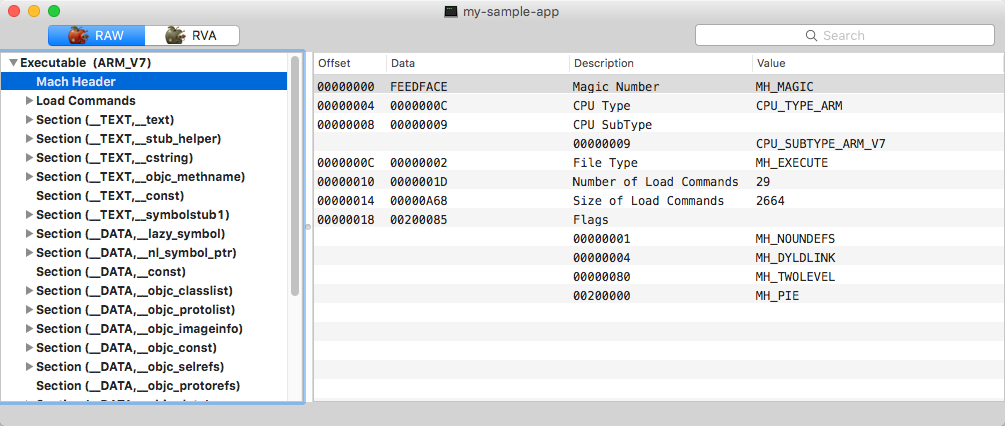 Mach Cabeçalho do executável no binário “thin
Mach Cabeçalho do executável no binário “thin
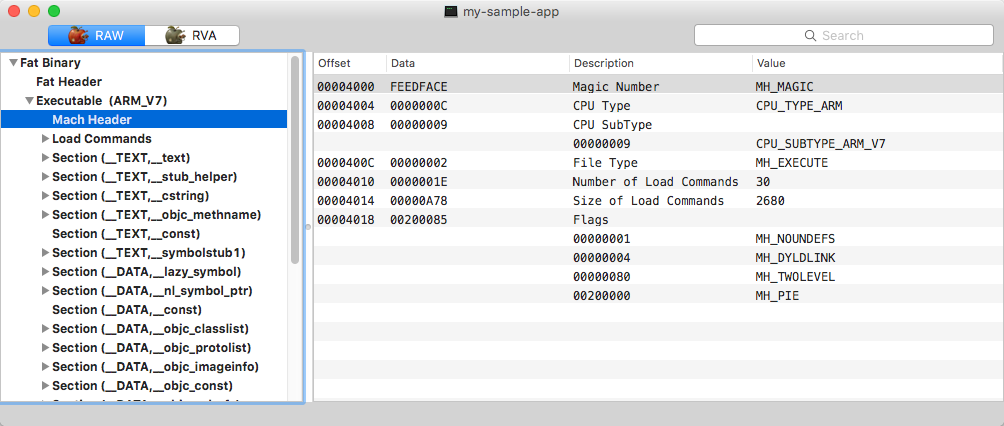 Cabeçalho Mach do primeiro executável no binário “fat
Cabeçalho Mach do primeiro executável no binário “fat
Cada cabeçalho mach começa com o número mágico 0xfeedface e contém informações gerais sobre o executável, como o tipo de CPU de destino, o subtipo, as opções de carregamento e a contagem e o deslocamento dos comandos de carregamento. Os comandos de carregamento fornecem as informações essenciais para o carregamento da imagem:
- Seções e segmentos do executável, bem como seu mapeamento para a memória virtual
- Caminhos de bibliotecas dinâmicas vinculadas
- Localização das tabelas de símbolos
- Assinatura de código
Segmentos. Grandes partes do executável que são mapeadas para um determinado espaço de endereço virtual pelo carregador são chamadas de segmentos. Os segmentos são divididos por seções, cada uma armazenando um determinado tipo de informação.
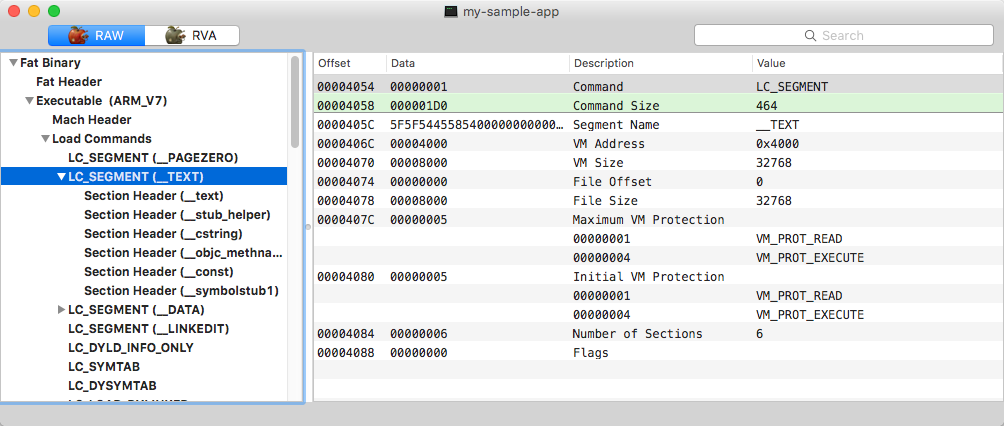 O segmento ‘TEXT’ (texto)
O segmento ‘TEXT’ (texto)
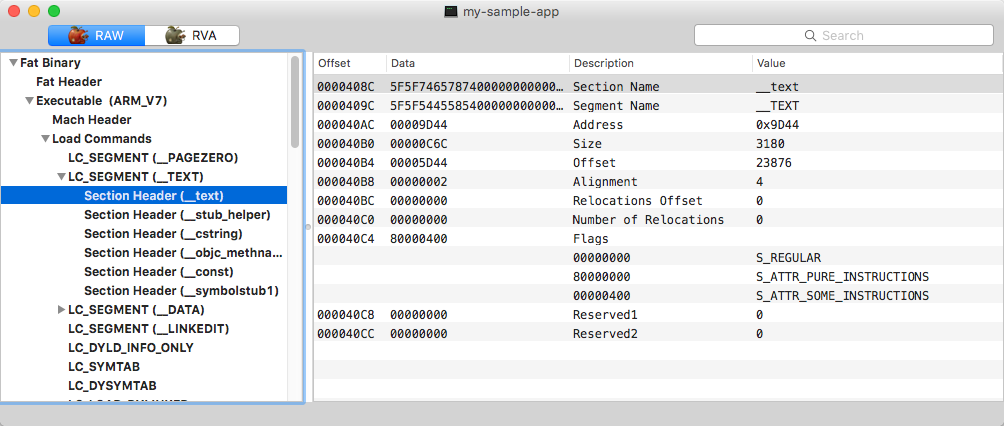 Seção ‘text’ do segmento ‘TEXT’
Seção ‘text’ do segmento ‘TEXT’
Todos os segmentos são fluxos de bytes. Eles começam com o tipo e o tamanho do comando, que podem variar de um comando para outro.
Comandos de carregamento. Os comandos de carregamento descrevem cada dependência de biblioteca dinâmica e incluem caminhos para os arquivos binários correspondentes. Além disso, os comandos de carregamento também incluem locais de importação e tabelas de stub, tabelas de símbolos, bem como a tabela que contém informações para o carregador dinâmico.
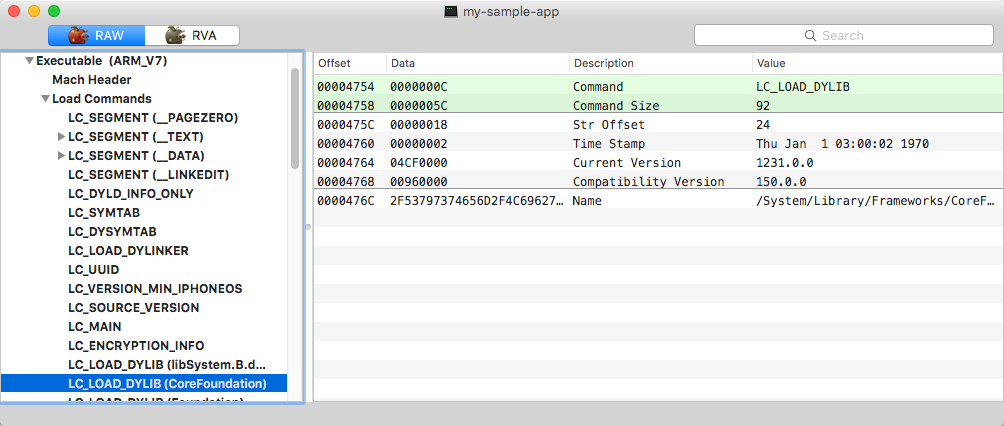 Comando Load para carregar o binário do CoreFoundation
Comando Load para carregar o binário do CoreFoundation
Tabelas de símbolos. Todos os símbolos usados no momento, definidos local e externamente, bem como os stubs, gerados por meio de chamadas externas executadas por meio da tabela de importação, estão contidos na tabela principal de símbolos.
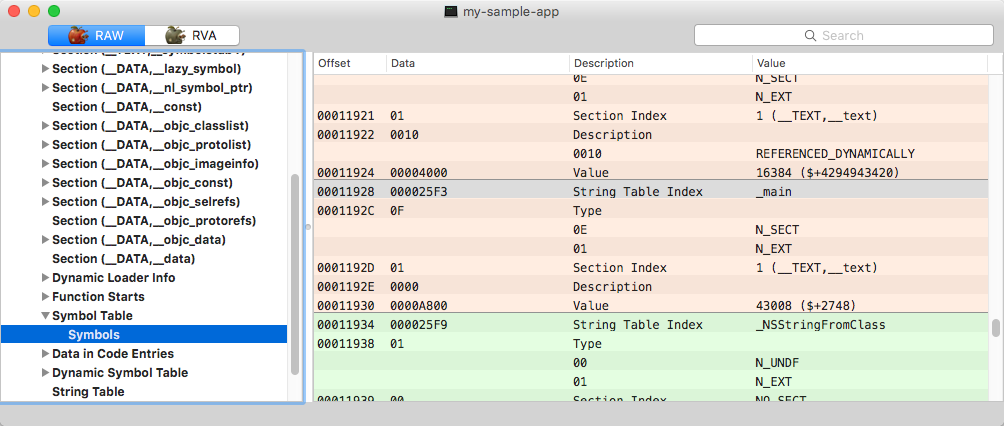 Tabela de símbolos
Tabela de símbolos
A tabela é dividida de acordo com o fato de o símbolo ser local, externo ou de depuração. Cada entrada representa uma determinada parte do código por meio da especificação do deslocamento do nome na tabela de strings, da seção ordinal, do tipo ou de qualquer outra informação específica.
Os nomes dos símbolos da tabela principal de símbolos estão contidos em uma tabela de strings separada. Outra tabela de símbolos dinâmicos vincula cada entrada da tabela de importação ao símbolo correspondente. Há também uma tabela separada com os dados necessários empregados pelo carregador dinâmico para cada símbolo externo.
Assinatura de código. Embora a assinatura de código esteja disponível gratuitamente por meio de código aberto, assim como em muitos outros projetos de código aberto, ela é muito mal documentada. Ela pode ser visualizada e gerenciada pela ferramenta de codesign que permite trabalhar com diferentes partes da assinatura. O local da assinatura de código no arquivo binário é fornecido pelo comando load correspondente.
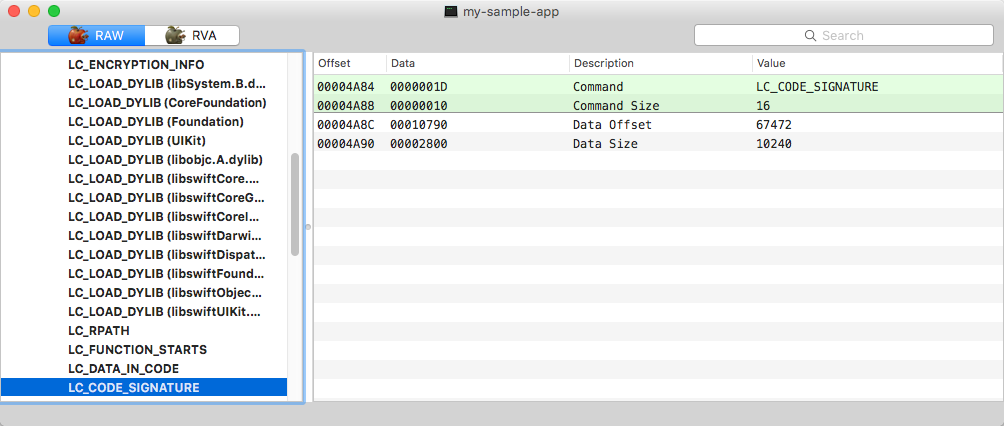 Comando de carregamento para assinatura de código
Comando de carregamento para assinatura de código
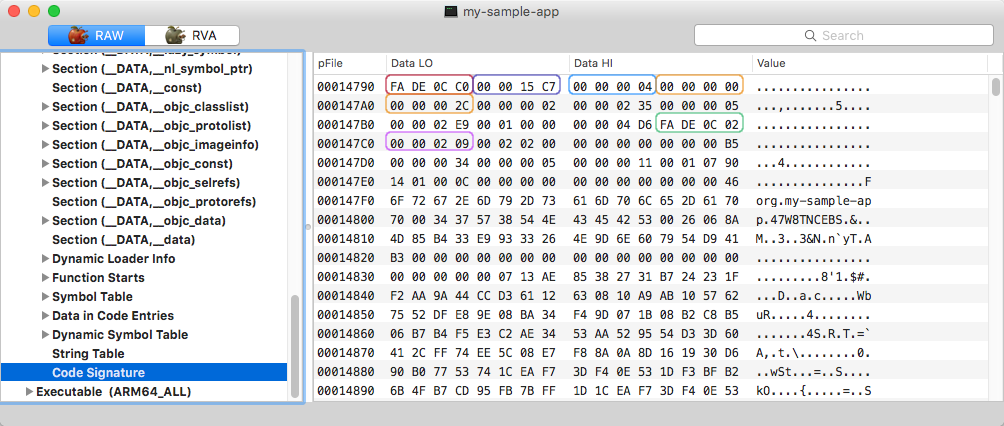 Assinatura de código bytestream
Assinatura de código bytestream
A própria assinatura de código contém seu próprio cabeçalho, que começa com a sequência de bytes:
- Número mágico (0xfade0cc0)
- Assinatura de código tamanho do blob
- Contagem de slots
O cabeçalho é seguido pelo par de bytes de indexação do slot de assinatura, em que o primeiro byte é um tipo e o segundo é um deslocamento do slot de assinatura. O offset aponta para o início de um determinado slot.
Cada slot começa com a sequência de dois bytes:
- Número mágico (0xfade0cc2)
- Tamanho do slot
Os slots de assinatura de código destinam-se a conter uma série de coisas importantes, como:
- Diretório de códigos
- Requisitos de assinatura
- Descrição do recurso selado
- Direitos
- Assinatura de código
A tabela de hashes, bem como o algoritmo de hash, o tamanho da página de código e o tamanho da tabela estão todos contidos no diretório de código. A tabela é dividida em parte positiva, que contém hashes de páginas de código executável, e parte negativa, que opcionalmente inclui hashes de diferentes partes de assinatura de código, bem como hash de info.plist.
Os direitos, os recursos e os requisitos de assinatura de código são simples bytestreams de arquivos específicos situados dentro do pacote.
O slot de assinatura de código sempre contém um diretório de código criptografado que usa o formato CMS.
O que mais o senhor precisa saber
Arquitetura. Atualmente, todos os dispositivos de desktop utilizam CPUs x86-64, enquanto os dispositivos móveis geralmente usam alguma variação da arquitetura ARMv7 ou ARMv8. Conhecer os conjuntos de instruções de uma determinada arquitetura de CPU é muito importante para o sucesso da engenharia reversa de algoritmos. Também é muito útil conhecer as convenções de chamada e várias especificidades do ARM, como o modo thumb ou o formato dos opcodes.
Caches. No software moderno, um único arquivo chamado cache compartilhado é usado para mesclar todas as estruturas do sistema e dylibs. Ele está localizado em /System/Library/Caches/com.apple.dyld/.
Ferramentas de engenharia reversa
O Mac oferece algumas ferramentas para engenharia reversa do iOS e do OS X prontas para uso. As ferramentas em questão incluem:
- lldb – depurador avançado
- otool – ferramenta de console que pode ser usada para visualizar o conteúdo dos executáveis Mach-O
- nm – permite visualizar nomes e símbolos contidos em executáveis Mach-O
- codesign – fornece informações detalhadas sobre assinaturas de código
Além disso, muitas ferramentas e utilitários de terceiros também estão disponíveis, o que pode ajudá-lo no processo de engenharia reversa do OS X e do iOS. Exemplos de tais ferramentas incluem:
- Interactive DisAssembler (IDA) – uma das ferramentas mais úteis e importantes para a realização de pesquisas complexas e detalhadas sobre executáveis.
- MachOView – em termos de funcionalidade, essa ferramenta freeware é semelhante ao otool e ao nm (pois permite visualizar a estrutura dos arquivos Mach-O), mas apresenta as informações de forma muito mais fácil e intuitiva por ter uma GUI. A principal desvantagem do MachOView é que ele é bastante instável.
- Class-dump – ferramenta que permite despejar declarações de classe em cabeçalhos normais de um executável.
- Hopper – excelente ferramenta shareware interativa para engenharia reversa de software iOS e OS X.
Conclusão
Aprender a fazer engenharia reversa de software OS X ou de aplicativos iOS pode ser um grande desafio. É necessário ter conhecimento avançado e experiência em programação para entender a estrutura do software e a intenção de quem o escreveu. No entanto, se o senhor se empenhar e se dedicar, qualquer pessoa pode aprender a fazer engenharia reversa de software OS X e iOS, e as habilidades adquiridas no processo o beneficiarão muito quando se tratar de aprimorar seu próprio software.



Sobre Dennis Turpitka
Dennis Turpitka, CEO da AprioritO senhor é especialista em design e desenvolvimento de negócios de soluções de segurança digital, projetos de P&D em virtualização e computação em nuvem, criação e gerenciamento de direção de pesquisa de software. Empresário bem-sucedido, que organizou várias start-ups de segurança.